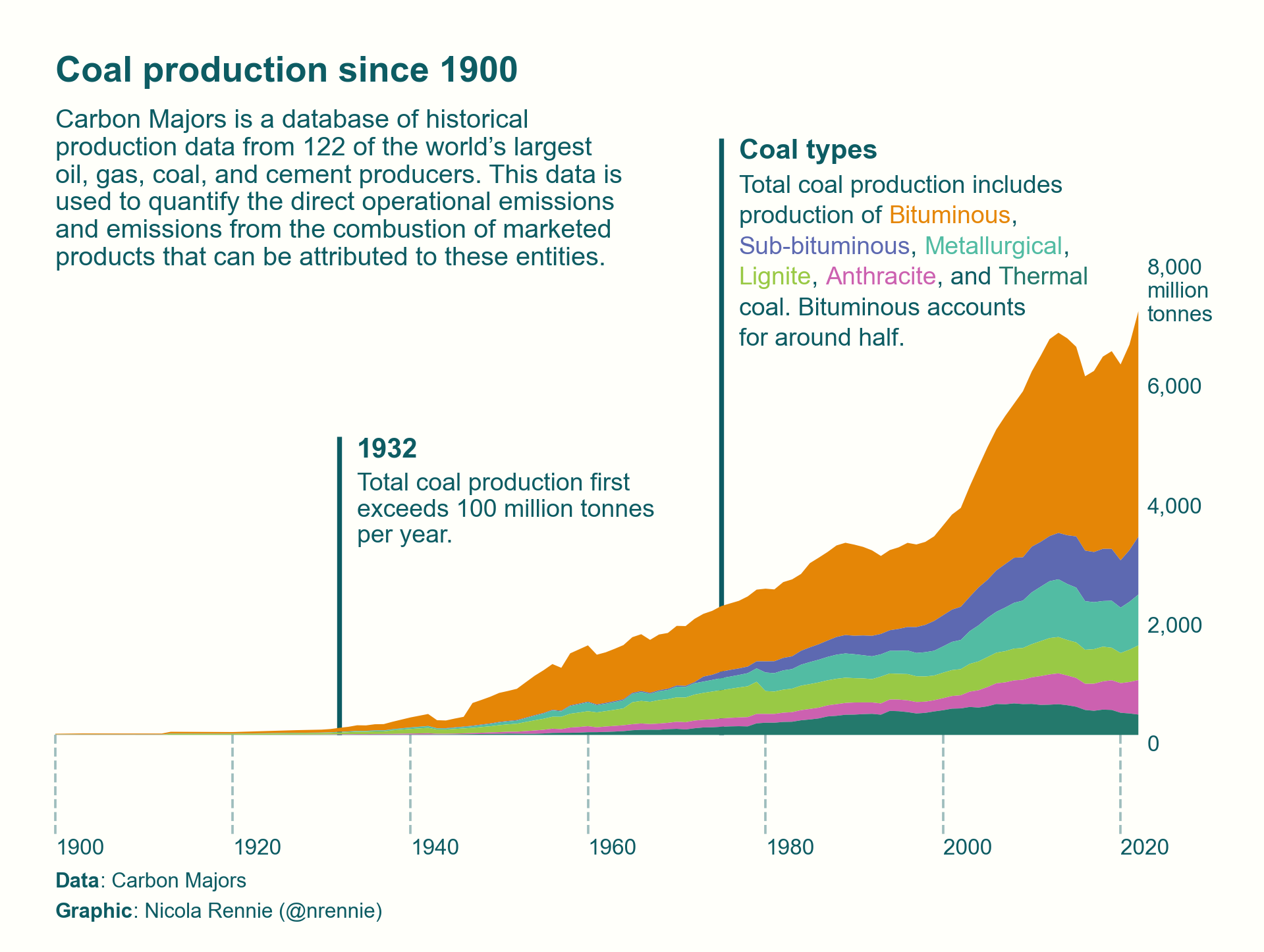
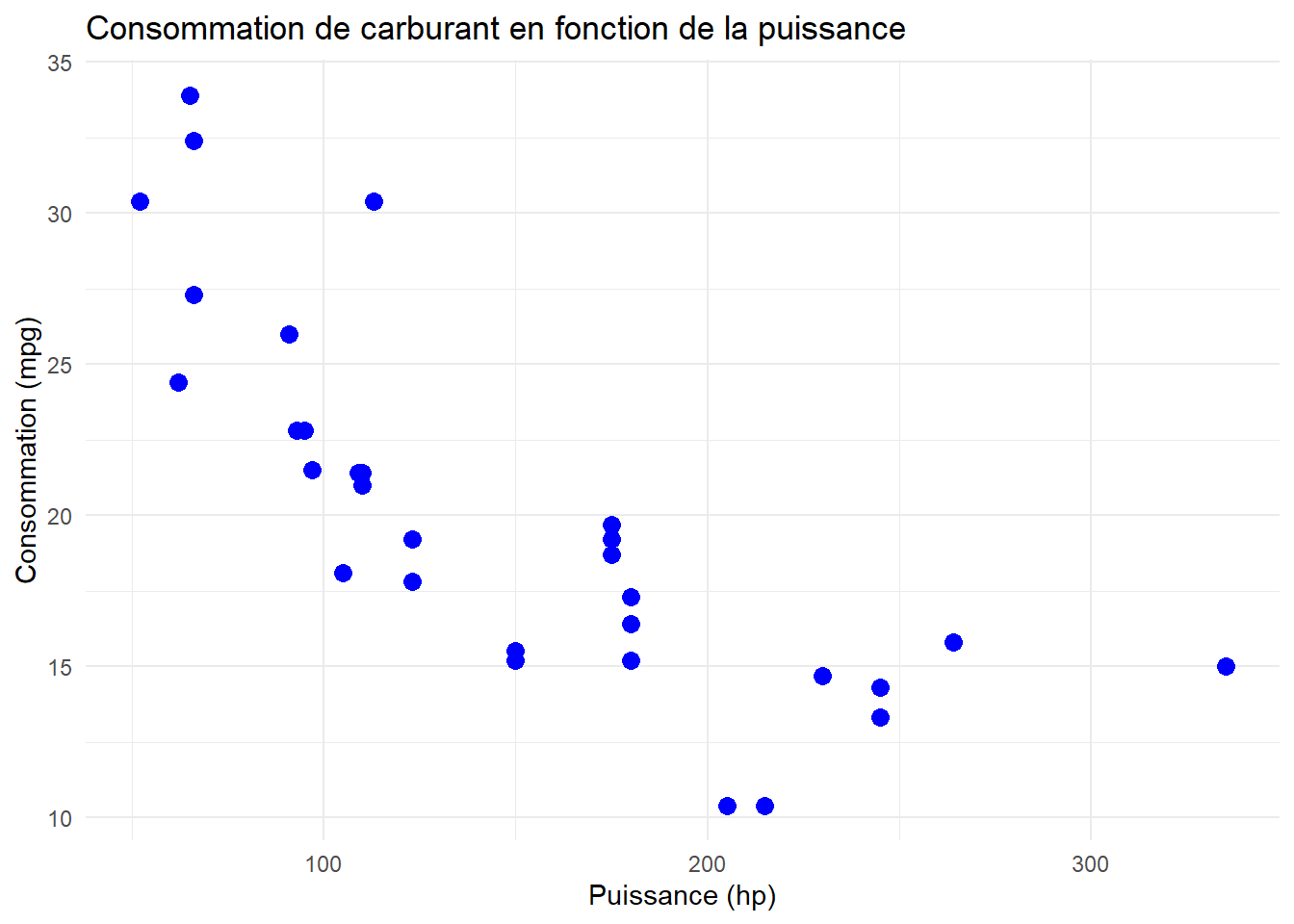
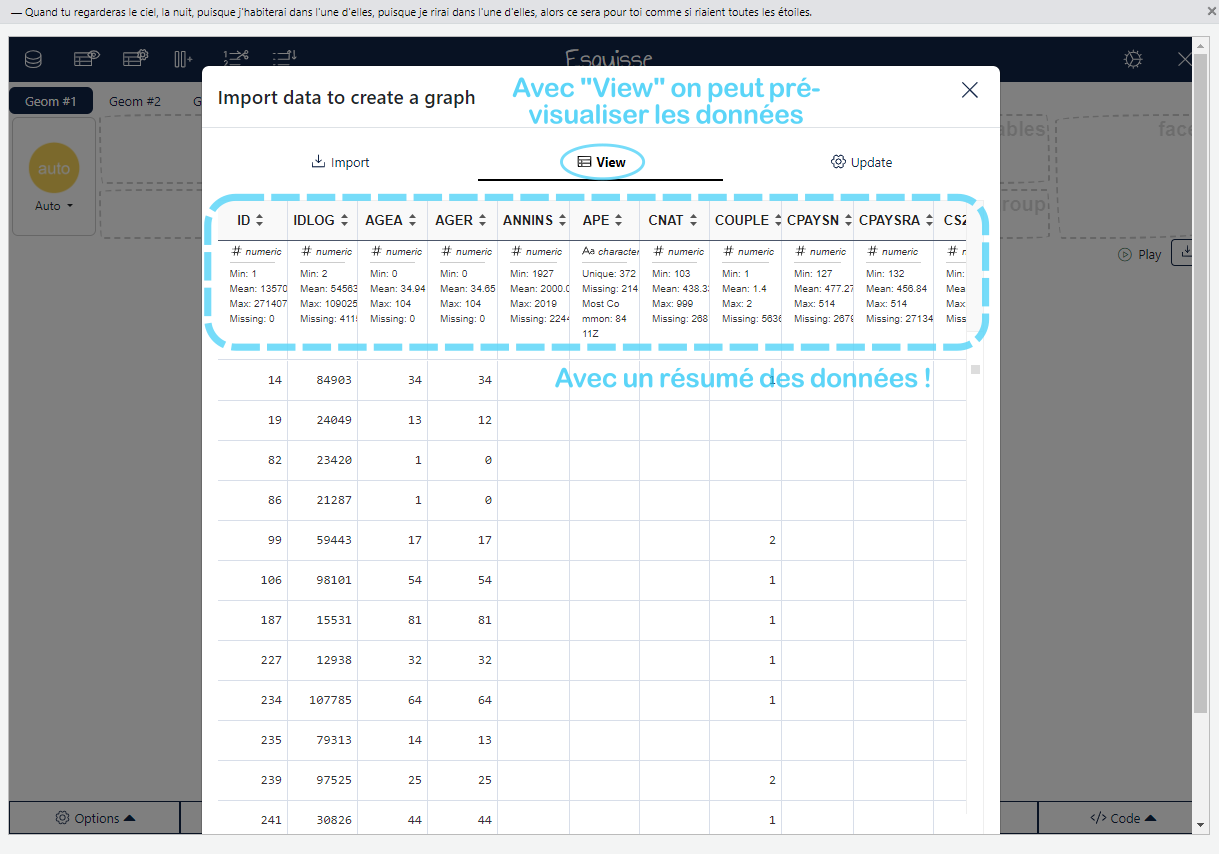
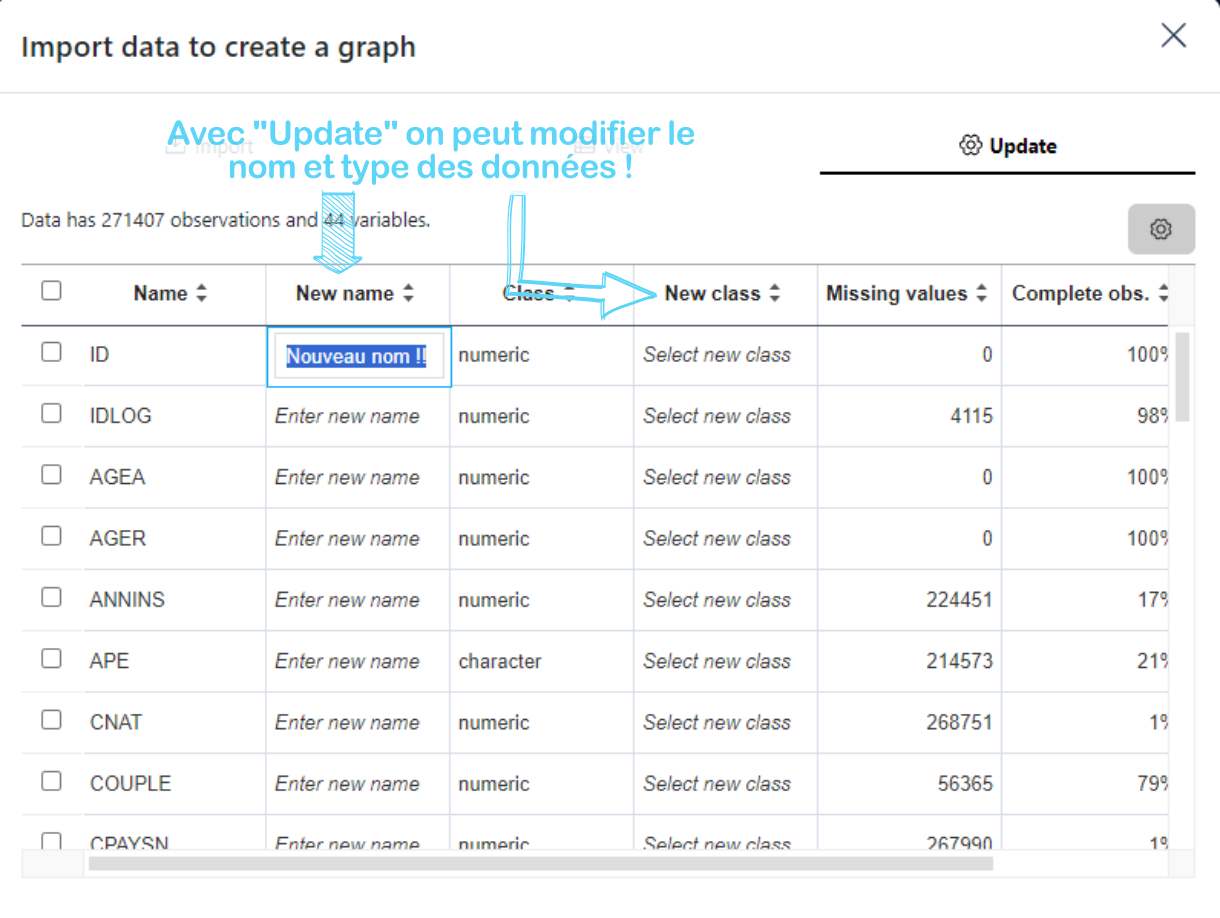
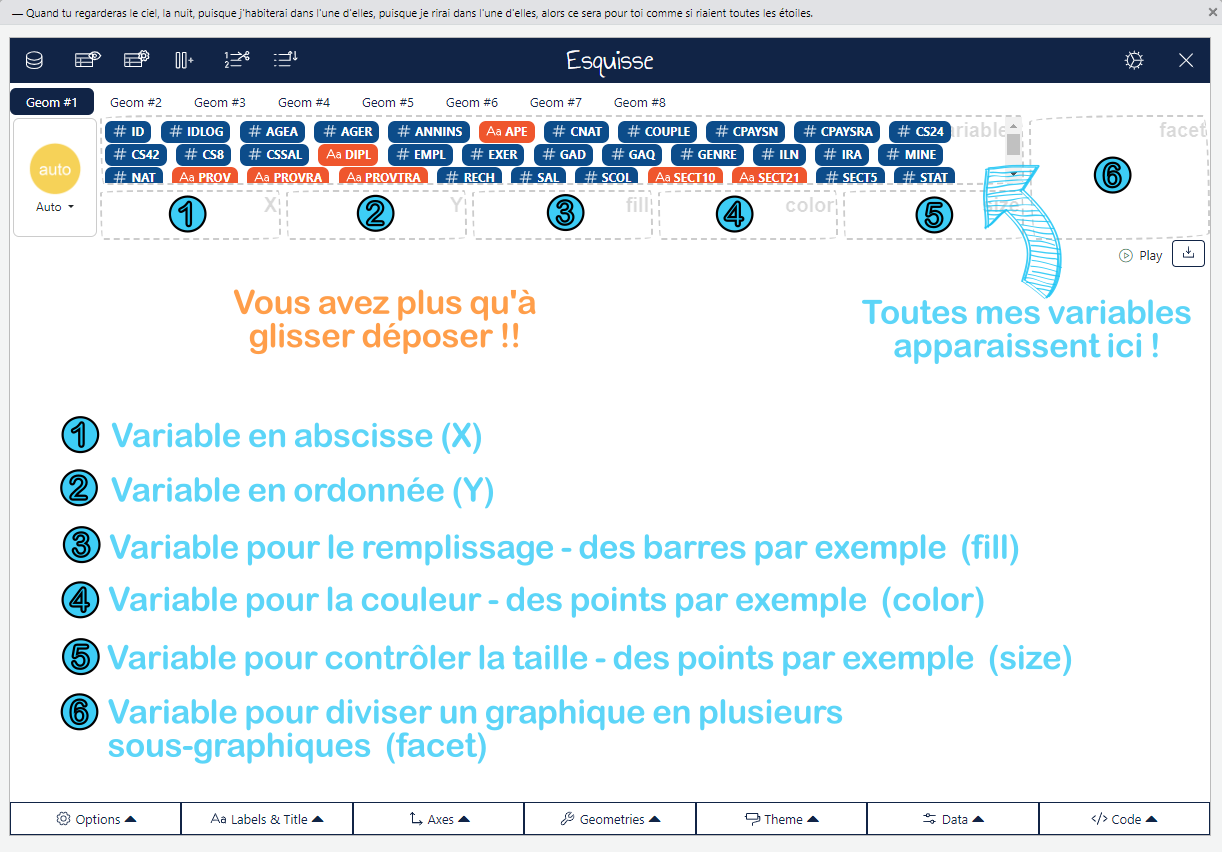
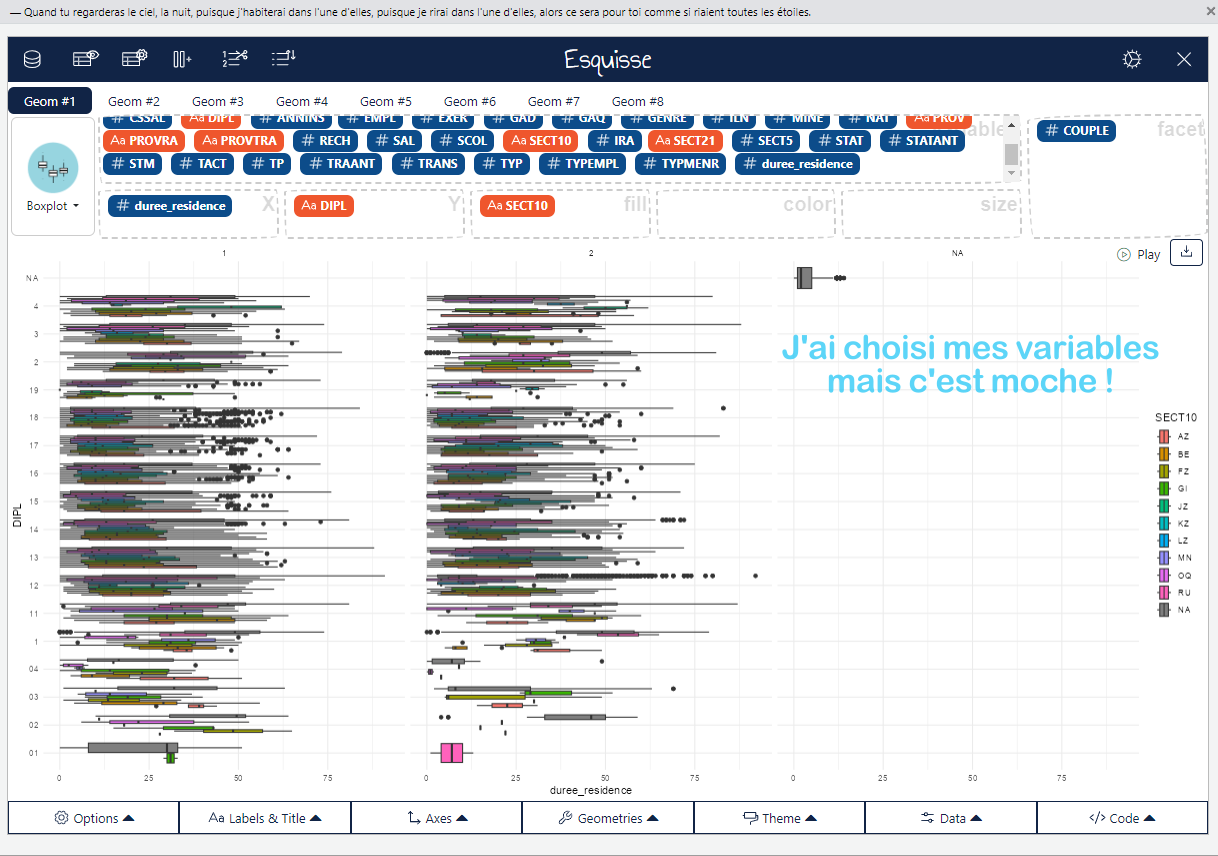
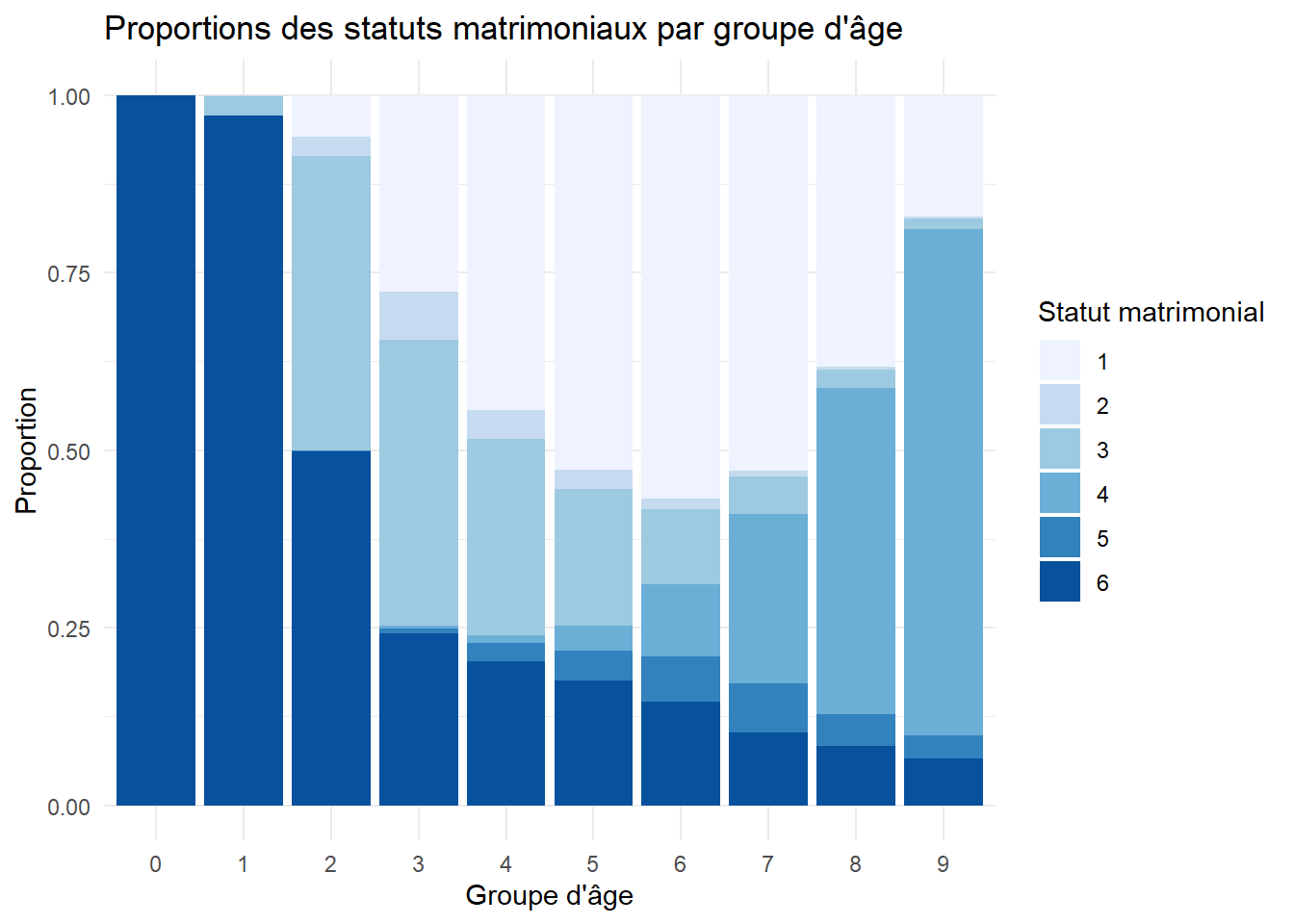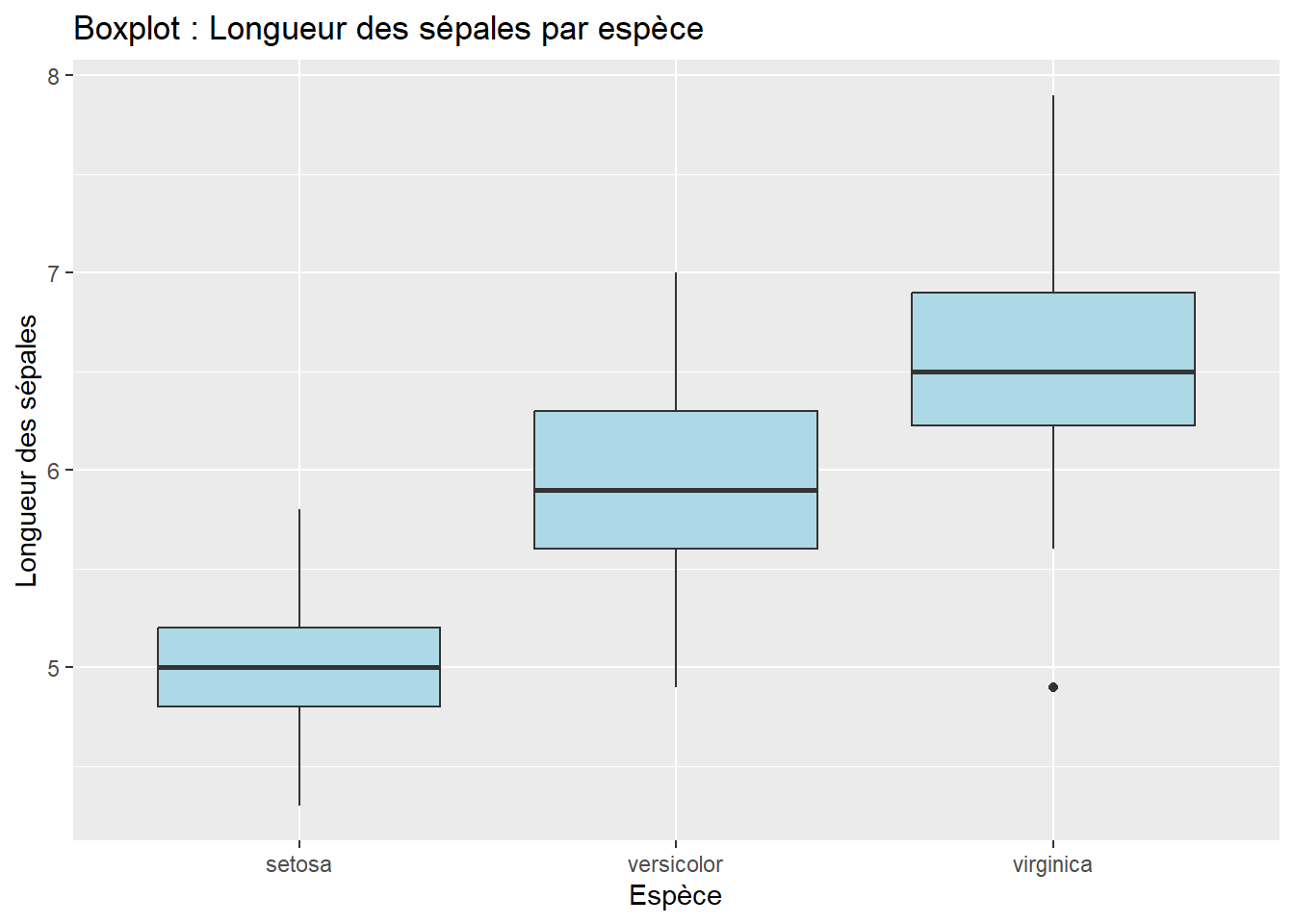Dans ce cours, vous allez apprendre à transformer des données brutes en graphiques clairs et efficaces avec R. La visualisation de données ne se limite pas à créer des images esthétiques — elle consiste à révéler des tendances cachées, à rendre les analyses compréhensibles, et à communiquer des résultats de manière convaincante. Que vous cherchiez à comparer des catégories, identifier des tendances ou explorer des relations entre variables, savoir comment et quand utiliser les bons graphiques est essentiel pour éviter les mauvaises interprétations et maximiser l’impact de vos analyses. Vous allez découvrir les outils essentiels et les meilleures pratiques pour rendre vos données parlantes et exploitables, tout en évitant les erreurs courantes.
II) Théorie
Etape 1 : Formulez la question principale de votre analyse
Avant de foncer tête baissée dans la création de graphiques, prenez un instant pour réfléchir : Quelle est la question principale que je dois répondre avec ces données ? C’est facile de se perdre dans l’excitation de visualiser des données sans avoir une idée précise. Mais sans une question directrice, vos graphiques risquent de devenir une distrcation plutôt qu’un véritable outil de communication. Pensez à cette question comme à au pilier de tout votre processus de visualisation. Voulez-vous comprendre des tendances ? Comparer des catégories ? Dévoiler des relations entre variables ?
Prenons un exemple basé sur les données du recensement de la population de Nouvelle-Calédonie 2019.
Exemple 1 : Imaginons que vous voulez savoir si l’âge a un impact sur la situation matrimoniale. Vous pourriez formuler votre question ainsi : Quel est le lien entre les différents groupes d’âge et le statut matrimonial ?
Pour répondre à cette question, vous pourriez commencer par explorer la variable AGEA (âge) et la variable STM (statut matrimonial légal) pour observer les tendances parmi les différents groupes d’âge (voir GAD - Groupe d’âge décennal dans le dictionnaire).
Exemple 2 : Si vous êtes intéressé par les habitudes de déplacement des jeunes adultes, une question pertinente pourrait être : Comment les jeunes adultes (20-30 ans) se déplacent-ils pour aller travailler selon leur secteur d’activité ?
Ici, vous pourriez utiliser les variables AGEA (âge atteint) et TRANS (mode de transport) ainsi que SECT21 (secteur d’activité en 21 postes) pour visualiser la répartition des modes de transport dans les différents secteurs d’activité. Cela vous permettrait de voir si certains secteurs sont associés à des modes de transport spécifiques (par exemple, les secteurs où la marche ou l’utilisation de la voiture sont plus fréquents).
Ces questions sont fondamentales car elles vont déterminer le type de graphique que vous allez construire : un diagramme en barres pour comparer des catégories, un scatter plot pour visualiser des corrélations, ou encore un histogramme pour comprendre la distribution des âges.
L’idée est donc de rester concentré sur la question. C’est elle qui guidera toutes vos décisions de visualisation.
Etape 2 : Élaborez des questions auxiliaires
Maintenant que vous avez bien défini votre question principale, il est temps de creuser un peu plus loin. Décortiquez cette grande question en petites parties plus gérables — appelons les des questions auxiliaires. Ce sont ces questions qui vont vous aider à comprendre le contexte et les détails de vos données. Prenons un exemple en lien avec la première question principale :
Quel est le lien entre les différents groupes d’âge et le statut matrimonial ?
Voici des questions auxiliaires que vous pourriez poser pour affiner votre analyse :
Quels sont les statuts matrimoniaux les plus fréquents parmi les différentes tranches d’âge ?
Cela vous aidera à comprendre la répartition de chaque groupe d’âge selon les catégories de la variable STM (statut matrimonial).
Existe-t-il une tranche d’âge spécifique où certains statuts matrimoniaux sont plus fréquents ?
Peut-être qu’une tranche d’âge particulière montre un pic pour un certain statut (par exemple, beaucoup de mariages dans la trentaine).
Comment la répartition de l’âge varie-t-elle en fonction du secteur d’activité chez les jeunes adultes (20-30 ans) ? Cela vous permettrait de visualiser si certains secteurs emploient principalement des jeunes ou si la distribution des âges est plus équilibrée dans d’autres secteurs.
Ces questions auxiliaires sont essentielles car elles vous guident dans l’exploration des nuances de vos données. En répondant à chacune de ces sous-questions, vous serez en mesure de construire des visualisations spécifiques qui capturent les subtilités de vos données, au lieu d’adopter une approche unique pour tous vos sujets (genre plein d’histogrammes redondants !).
L’objectif est de décomposer le problème pour trouver les angles cachés dans vos données. Plus vous creusez, plus vous êtes en mesure de produire des graphiques pertinents et éclairants !
Etape 3 : Identifier les expressions clés dans vos questions pour choisir le type de représentation
Voici une étape cruciale : traduire vos questions en choix visuels. Le tout est de trouver un lien entre les mots-clés présents dans vos questions et les types de visualisations adaptés.
Comment on fait ça ?
Si votre question inclut des expressions comme “comparer des catégories”, il faudrait vous orienter vers des diagrammes en barres, des graphes à points, ou des diagrammes en colonnes.
Si votre question contient “montrer les tendances au fil du temps”, il est probable que vous ayez besoin de graphes linéaires, de graphes en aires, ou de graphes de séries temporelles.
Et pour des termes tels que “distribution” ou “répartition”, vous vous dirigerez plutôt vers des histogrammes, des boxplots, ou des diagrammes en violon.
Exemple de correspondance entre les questions et les graphiques :
Prenons un exemple concret basé sur nos questions du recensement de la Nouvelle-Calédonie.
Question principale : Quel est le lien entre les différents groupes d’âge et le statut matrimonial ?
Ici, les mots-clés “différents groupes d’âge” et “statut matrimonial” suggèrent que l’on compare des catégories. Vous pouvez utiliser un diagramme en barres empilées ou un diagramme en colonnes groupées pour voir comment les proportions des différents statuts matrimoniaux varient selon les groupes d’âge.
Fonction utilisée :geom_bar(position = "fill") pour un diagramme en barres empilées.
Code
# Psst : Ne t'occuppes pas du code pour le moment, on verra ça plus tard !ggplot(data = RP2019NC_OD_ind_3Provinces, aes(x =as.factor(GAD), fill =as.factor(STM), group = STM)) +geom_bar(position ="fill") +scale_fill_brewer(palette ="Blues") +# Palette sobre de tons bleuslabs(title ="Proportions des statuts matrimoniaux par groupe d'âge",x ="Groupe d'âge",y ="Proportion",fill ="Statut matrimonial") +theme_minimal()
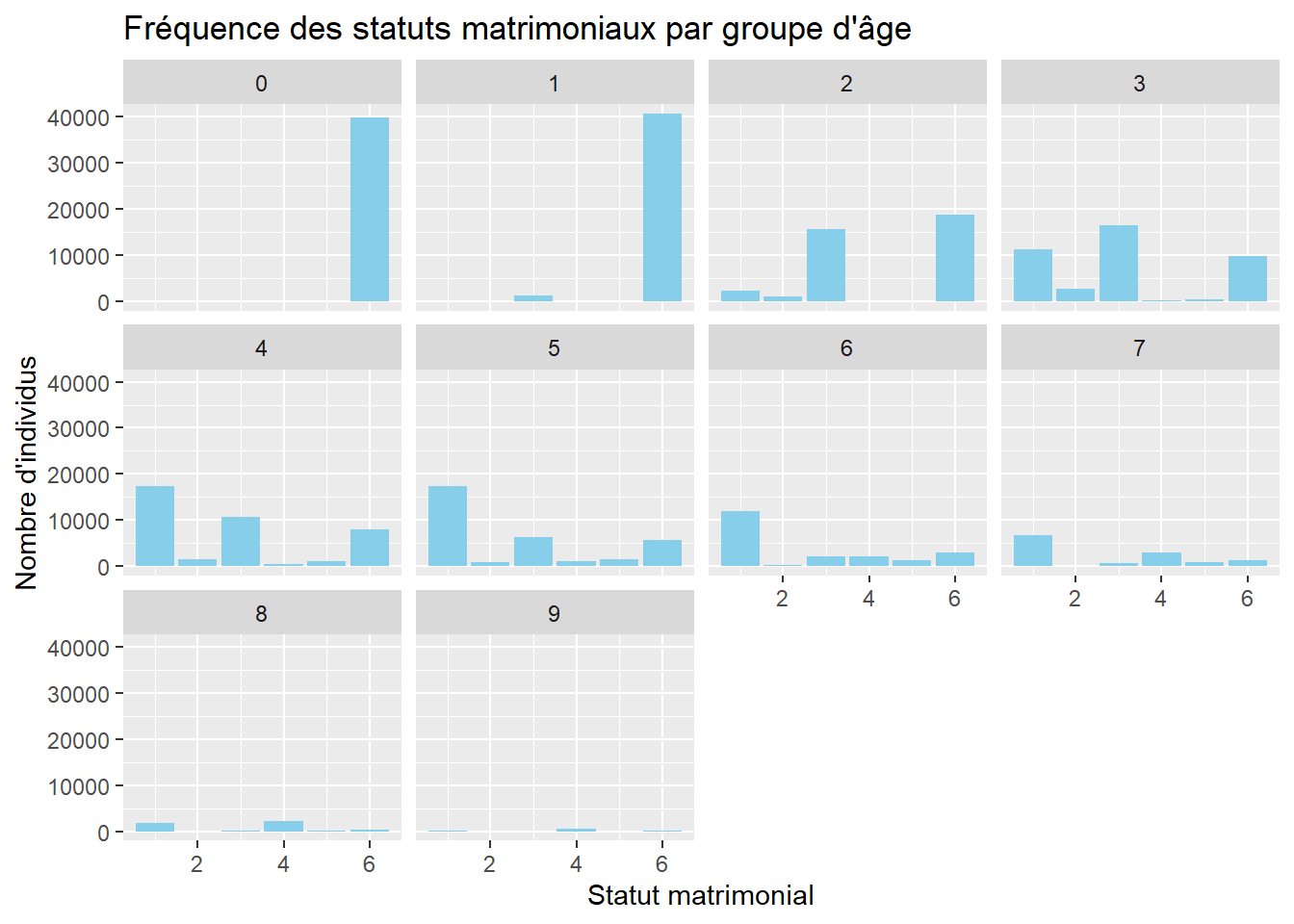
Question auxiliaire : Quels sont les statuts matrimoniaux les plus fréquents parmi les différentes tranches d’âge ?
Le mot-clé “fréquence” pointe vers un diagramme en barres, parfait pour visualiser la répartition des statuts matrimoniaux au sein de chaque groupe d’âge. On réalise un graphique par groupe d’âges afin d’y voir plus clair :)
Fonction utilisée :geom_bar() pour un diagramme en barres.
Code
ggplot(data = RP2019NC_OD_ind_3Provinces, aes(x = STM)) +geom_bar(fill ="#87CEEB") +# Bleu ciel plus douxfacet_wrap(~ GAD) +labs(title ="Fréquence des statuts matrimoniaux par groupe d'âge",x ="Statut matrimonial",y ="Nombre d'individus")
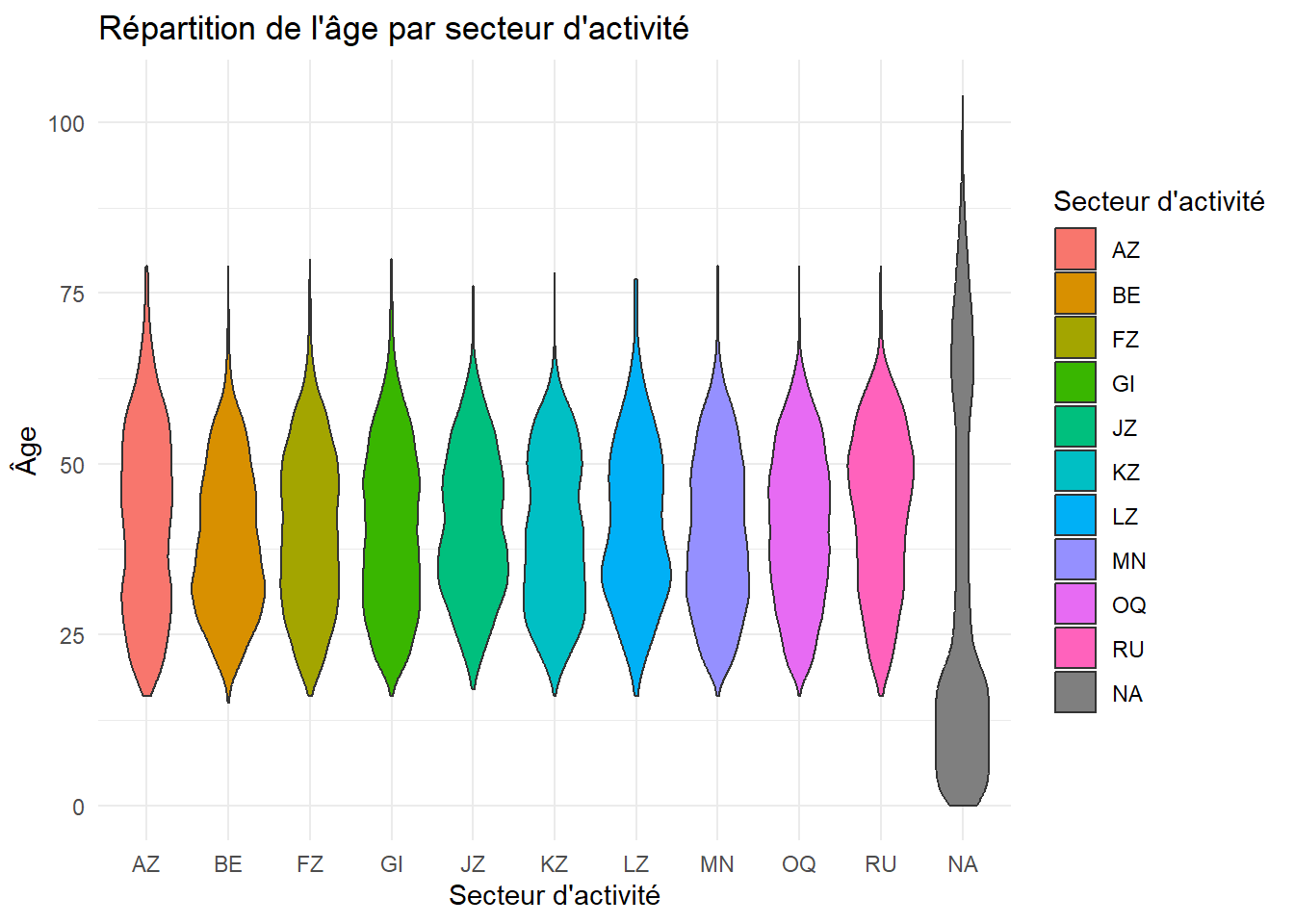
Question auxiliaire : Comment la répartition de l’âge varie-t-elle en fonction du secteur d’activité chez les jeunes adultes (20-30 ans) ?
Ici, nous pourrions examiner la répartition de l’âge des jeunes adultes dans les différents secteurs d’activité (variable SECT10). Cela permet de visualiser comment l’âge des employés varie dans chaque secteur, ce qui peut révéler des tendances intéressantes, comme la concentration de jeunes adultes dans certains secteurs spécifiques ou une distribution plus équilibrée dans d’autres.
Un violin plot serait un excellent choix pour montrer la distribution des âges dans chaque secteur d’activité. Ce type de graphique permet de visualiser la forme de la distribution des âges dans chaque secteur, tout en montrant les zones où les âges sont plus concentrés.
Fonction utilisée :geom_violin() pour visualiser la répartition des modes de transport
Code
ggplot(data = RP2019NC_OD_ind_3Provinces %>%filter(!is.na(AGEA)), aes(x = SECT10, y = AGEA, fill = SECT10)) +geom_violin() +labs(title ="Répartition de l'âge par secteur d'activité",x ="Secteur d'activité",y ="Âge",fill ="Secteur d'activité") +theme_minimal()
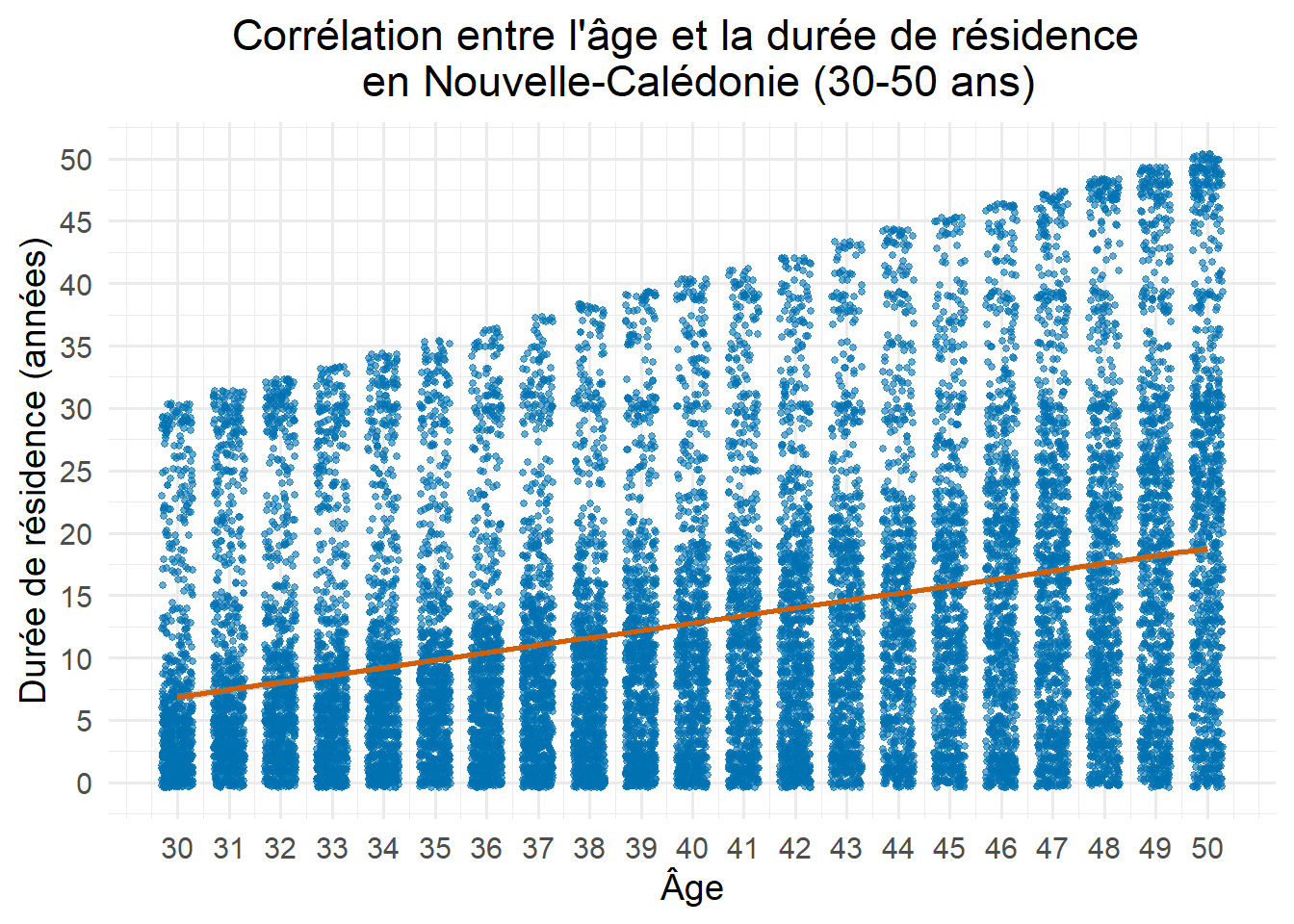
Question bonus : Existe-t-il une relation entre l’âge et la durée de résidence en Nouvelle-Calédonie chez les adultes (20-50 ans) ?
Pour cette question, nous utiliserons la variable AGEA (âge atteint) et ANNINS (année d’installation en Nouvelle-Calédonie). Nous pouvons calculer le nombre d’années de résidence en soustrayant l’année d’installation à l’année du recensement (2019) et ensuite créer un nuage de points pour visualiser la relation.
Fonction utilisée :geom_point() avec geom_smooth() pour ajouter la régression linéaire.
Code
pourMonPlot <- RP2019NC_OD_ind_3Provinces %>%mutate(duree_residence =2019- ANNINS) %>%filter(!is.na(ANNINS))ggplot(data = pourMonPlot %>%filter(AGEA >=30& AGEA <=50, !is.na(duree_residence)), aes(x = AGEA, y = duree_residence)) +geom_jitter(width =0.3, size =1, alpha =0.6, color ="#0072B2") +# Points plus petits, transparents et espacésgeom_smooth(method ="lm", se = T, color ="#D55E00", size =1) +# Ligne de régression affinéelabs(title ="Corrélation entre l'âge et la durée de résidence \n en Nouvelle-Calédonie (30-50 ans)",x ="Âge",y ="Durée de résidence (années)") +scale_x_continuous(breaks =seq(30, 50, by =1)) +# Gradations de l'axe Xscale_y_continuous(breaks =seq(0, 50, by =5)) +# Gradations de l'axe Ytheme_minimal(base_size =14) +# Thème minimal avec une taille de police plus grandetheme(plot.title =element_text(hjust =0.5)) # Centrer le titre
Etape 4 : Classifier les visualisations en fonction de votre audience
Ok, un truc à bien se mettre en tête c’est que tous les graphiques ne conviennent pas à toutes les audiences. Des graphiques magnifiquement complexes peubent ne pas fonctionner lors de présentations, tout simplement parce qu’ils dépassent les compétences de l’audience.
Voila donc trois catégories de graphiques :
À éviter absolument : Ce sont les graphiques problématiques — ceux qui ont tendance à induire en erreur ou à créer de la confusion, comme les diagrammes en barres 3D ou les camemberts avec trop de segments. Même pour des audiences expérimentées, ces graphiques peuvent être difficiles à interpréter correctement. De manière générales, bannir les “camemberts” car l’oeil humain est meilleur pour comparer des distances que des zones ! (a voir dans cet article !)
À utiliser seulement pour une audience experte ou technique : Des visualisations comme les heatmaps, les violin plots ou les graphes de coordonnées parallèles sont excellents pour une analyse approfondie mais nécessitent un certain niveau en matière d’analyse de données pour être bien interprétées. Elles sont idéales pour des équipes techniques, mais peuvent dérouter une audience moins expérimentée.
Toujours efficace : Ce sont les graphiques fiables et intuitifs, comme les graphes en lignes, les diagrammes en barres ou les scatter plots. Ces visualisations sont claires, faciles à comprendre et fonctionnent bien avec presque toutes les audiences. Elles sont vos alliés pour des présentations efficaces qui transmettent l’information de manière précise.
Etape 5 : Choisissez un type de graphique et personnalisez-le en fonction des questions
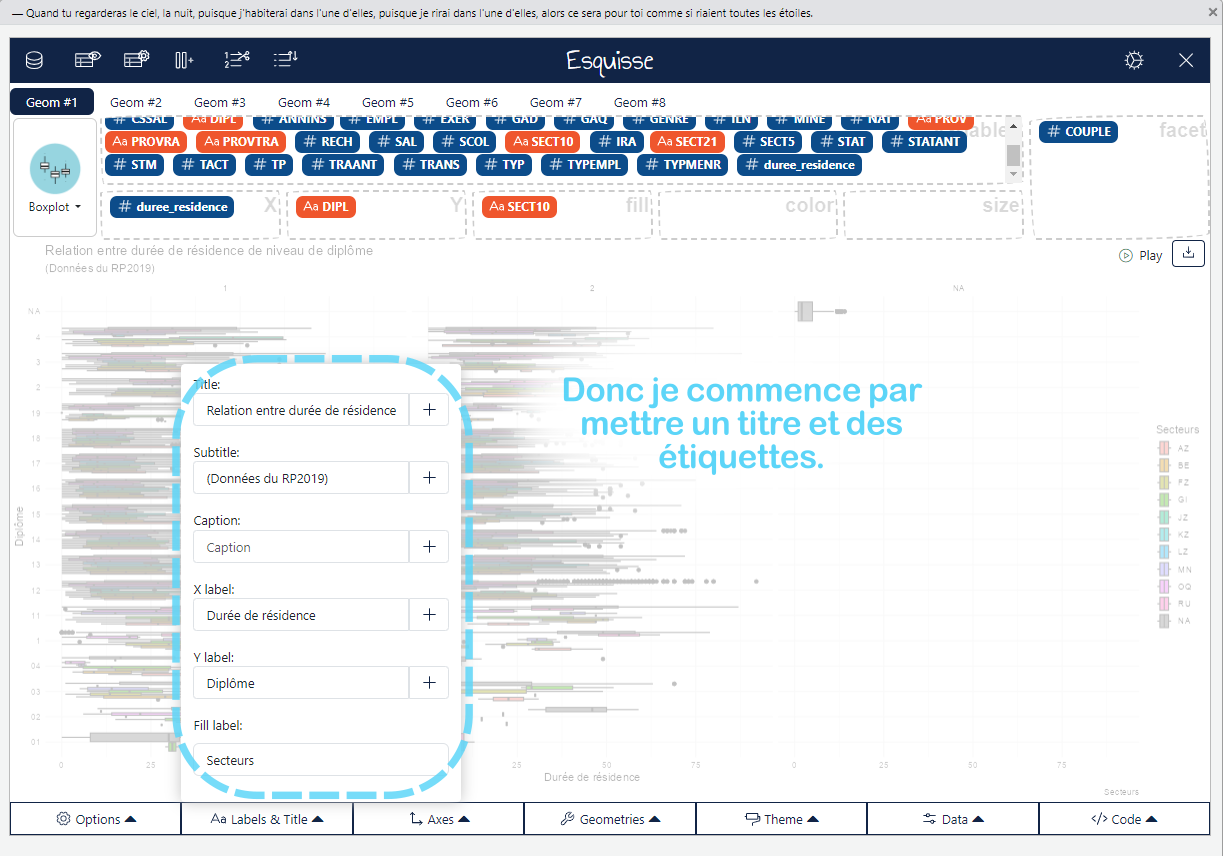
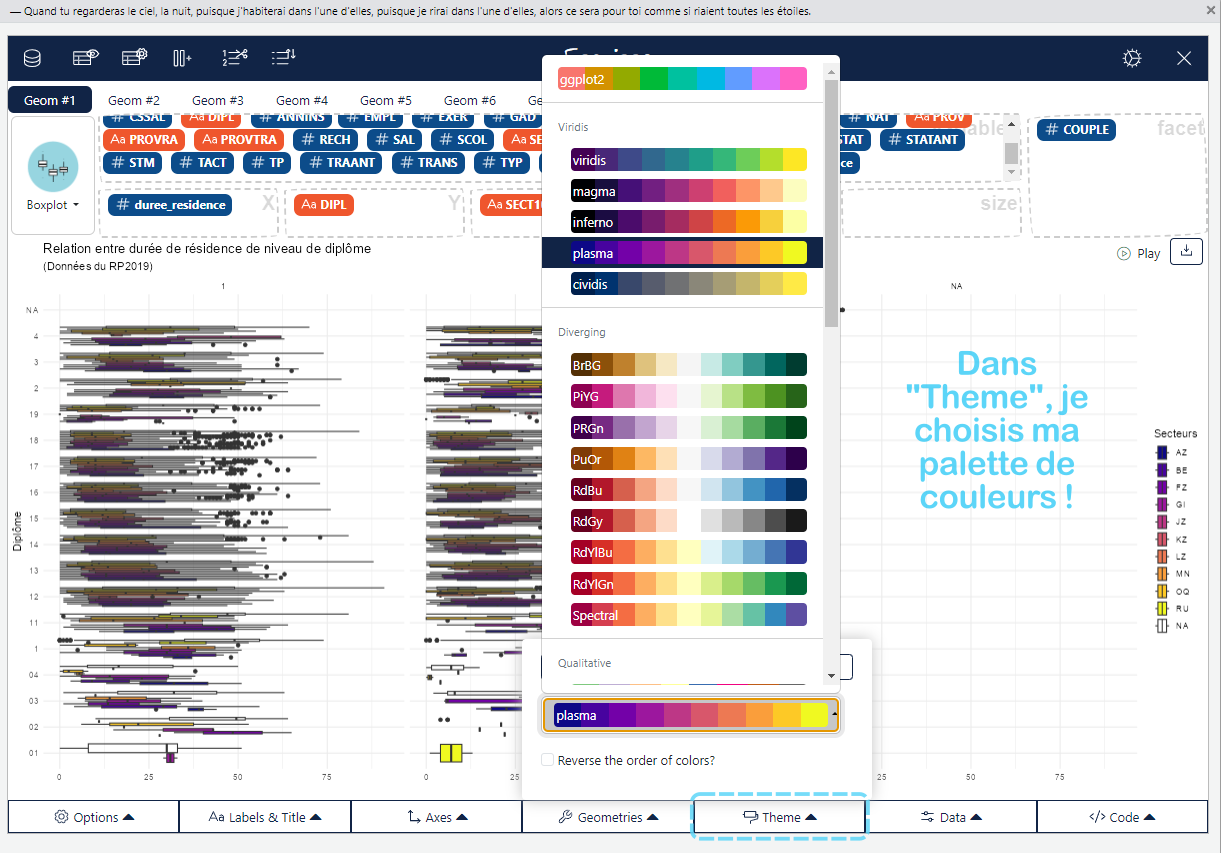
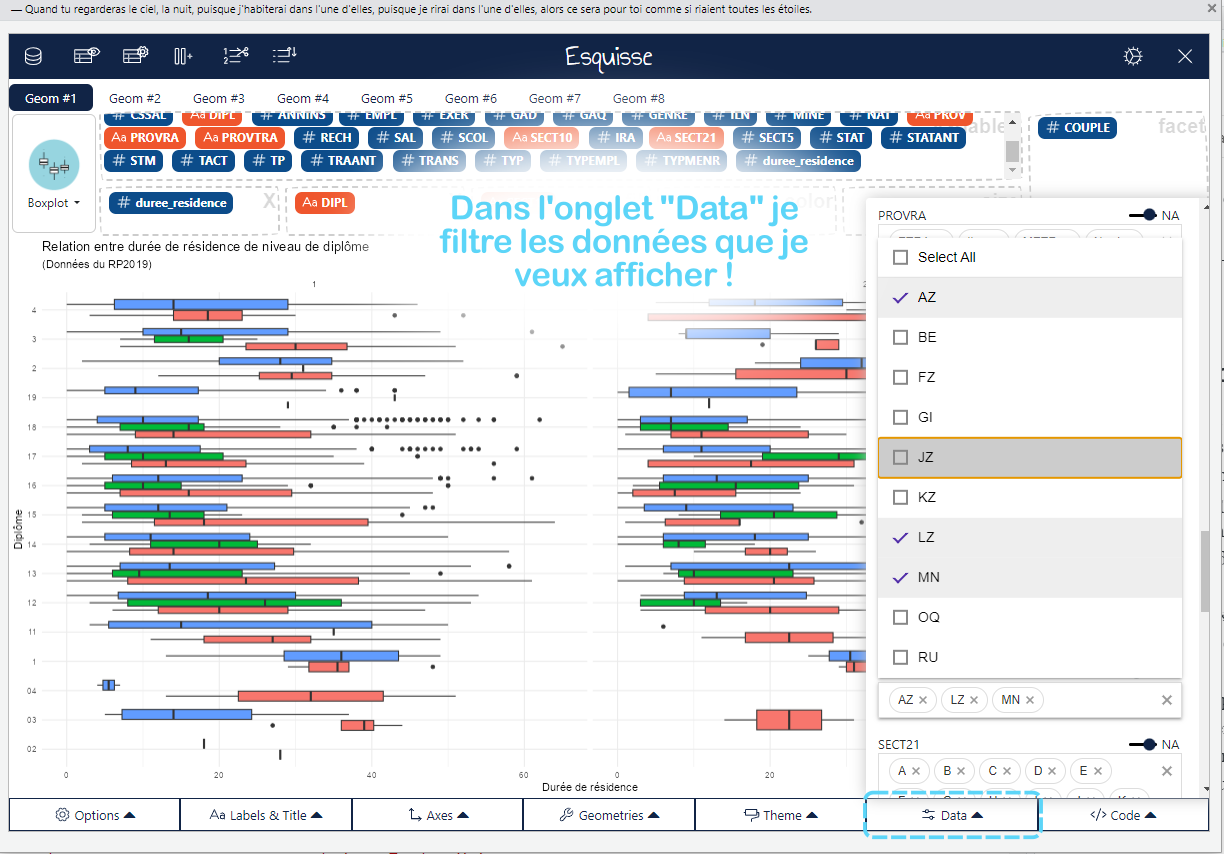
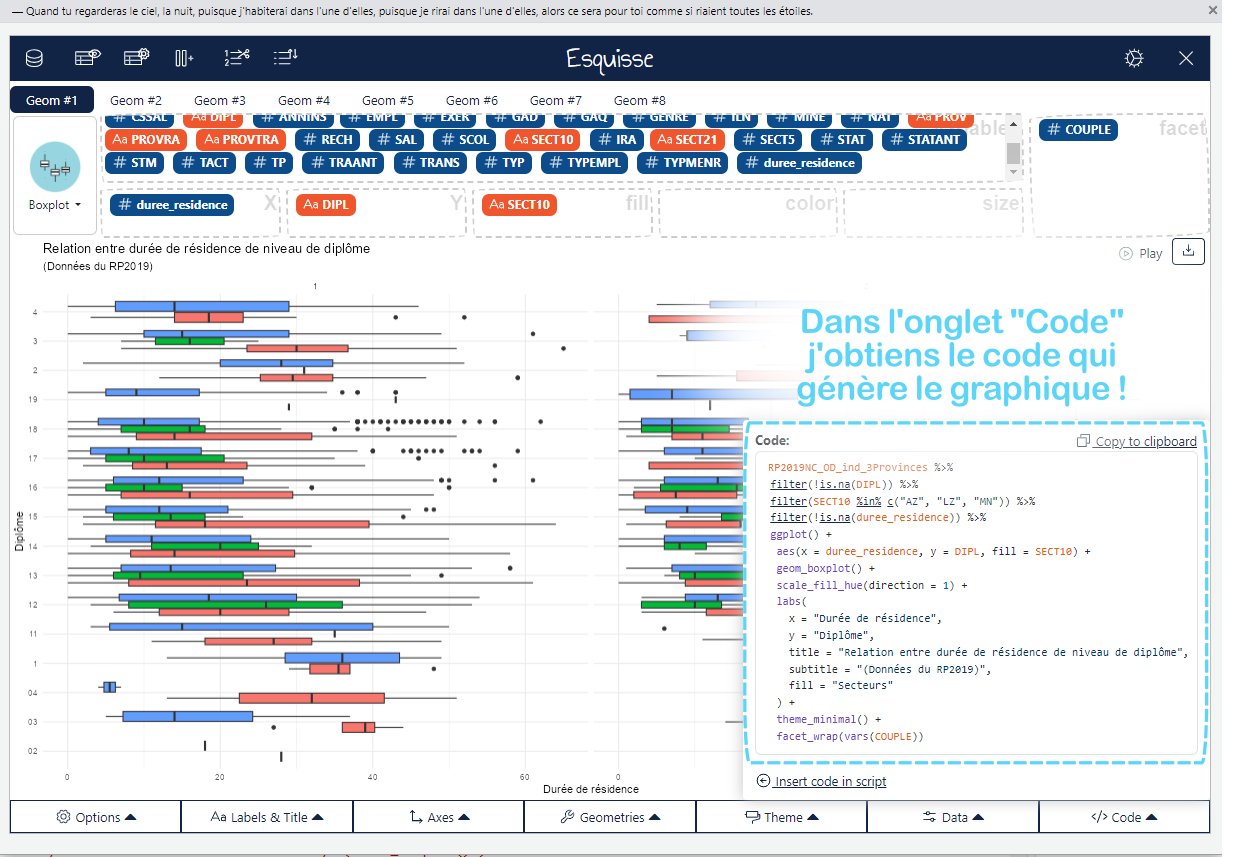
Une fois que vous avez réduit vos options à un type de graphique spécifique, il est temps de faire un choix. Mais ne vous arrêtez pas là ! Revenez à vos questions principales et questions auxiliaires pour voir s’il y a des détails spécifiques à mettre en valeur. C’est ici que la personnalisation entre en jeu — annotations, points de données marquants, schémas de couleurs et étiquettes d’axes peuvent tous être ajustés pour faire ressortir les informations clés. Vous pouvez même ajouter une petite carte, un dessin que vous avez fait sur paint, etc ! Vous pouvez aller vraiment loin dans cet exercice. Par exemple, le graphique suivant à été réalisé à 100% avec GGPLOT (le fameux package de création de graphiques) !
Conseils de personnalisation :
Utilisez les couleurs à bon escient : Utilisez des couleurs pour mettre en avant des points de données ou des tendances clés, mais évitez de surcharger les sens de votre audience avec trop de couleurs. Par exemple, si vous montrez la répartition des âges dans différents secteurs d’activité, vous pouvez utiliser une couleur contrastante pour un secteur particulier que vous souhaitez souligner.
Les annotations sont importantes : Ajouter du texte pour souligner des points critiques peut guider votre audience à travers l’histoire que vous racontez avec les données. Par exemple, si vous identifiez une tranche d’âge où un statut matrimonial est particulièrement fréquent, une annotation près du pic de fréquence peut attirer l’attention du public.
Éléments interactifs : Si vous présentez vos données dans un tableau de bord interactif, des éléments comme des info-bulles ou des filtres peuvent apporter de la profondeur à la visualisation. Cela permet à l’audience d’explorer les données en fonction de ses propres centres d’intérêt et de poser des questions supplémentaires.
III) Comment fonctionne GGplot2 ?
GGplot2, c’est une vraie galère au début. Personnellement, il m’a fallu du temps pour en maîtriser les bases. Pourtant, une fois que vous comprenez comment et pourquoi GGplot fonctionne de cette manière, vous découvrirez à quel point c’est un outil puissant et flexible pour la visualisation de données. Et oui, même si des assistants comme Esquisse ou ChatGPT peuvent vous aider, rien ne remplace la compréhension des fondamentaux de GGplot.
Alors, comment fonctionne GGplot2 ? C’est plus simple qu’il n’y paraît, surtout quand on le décompose étape par étape.
1. La philosophie derrière GGplot2 : La “Grammaire des graphiques”
GGplot2 repose sur l’idée de la grammaire des graphiques. Cela signifie que chaque graphique que vous créez est construit de la même manière qu’une phrase dans une langue : avec des composants bien définis (sujet, verbe, complément), qui peuvent être modifiés ou combinés pour dire quelque chose de différent.
Les données : Ce sont les “sujets”, la source. C’est la base de votre graphique, ce que vous voulez représenter.
Les géométries (geom_) : Ce sont les “verbes”. Elles définissent comment vous voulez représenter vos données (points, barres, lignes, etc.).
Les esthétiques (aes) : Ce sont les “compléments”. Elles indiquent quelles variables sont représentées sur l’axe X, l’axe Y, par des couleurs, des tailles, etc.
2. Construire un graphique en couches (layers)
GGplot2 fonctionne en “empilant” les composants les uns sur les autres, un peu comme des couches. Chaque couche ajoute quelque chose au graphique final.
Voici un schéma simple de construction d’un graphique avec GGplot2 :
Les données : Quelle variable sur l’axe X et quelle variable sur l’axe Y ? C’est ce que vous spécifiez dans aes().
Le type de géométrie : Comment voulez-vous afficher ces données ? Points, lignes, barres ? C’est là que les fonctions comme geom_point(), geom_bar() ou geom_line() interviennent.
Personnalisation : Ajoutez des couleurs, des légendes, des titres, etc. Cela peut se faire à travers des fonctions comme labs(), scale_color_manual(), ou encore theme().
Exemple simple pour mieux comprendre :
Ici, pas d’exemple du RP2019, on prend mtcars, le jeu de données simple et universel ! Vous transposerez !
2.1. La base : Les données et l’esthétique
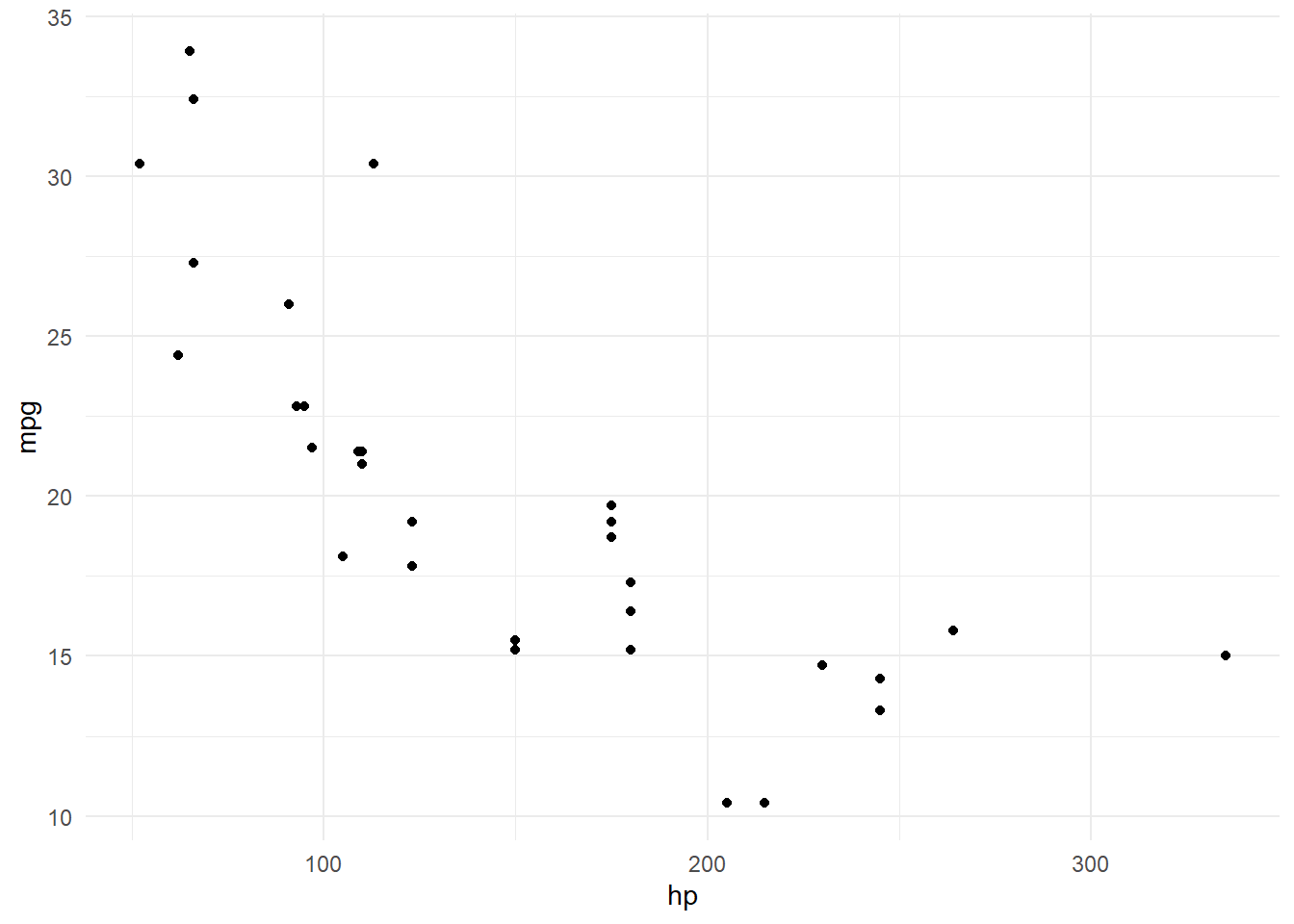
ggplot(data = mtcars, aes(x = hp, y = mpg))
Dans cette ligne, on a spécifié les données : mtcars est notre base, et dans l’esthétiqueaes on a défini que hp (puissance) sera l’axe X et mpg (consommation) sera l’axe Y. Mais ici, rien ne s’affiche encore, car nous n’avons pas ajouté de “verbe”.
2. Ajout de la géométrie
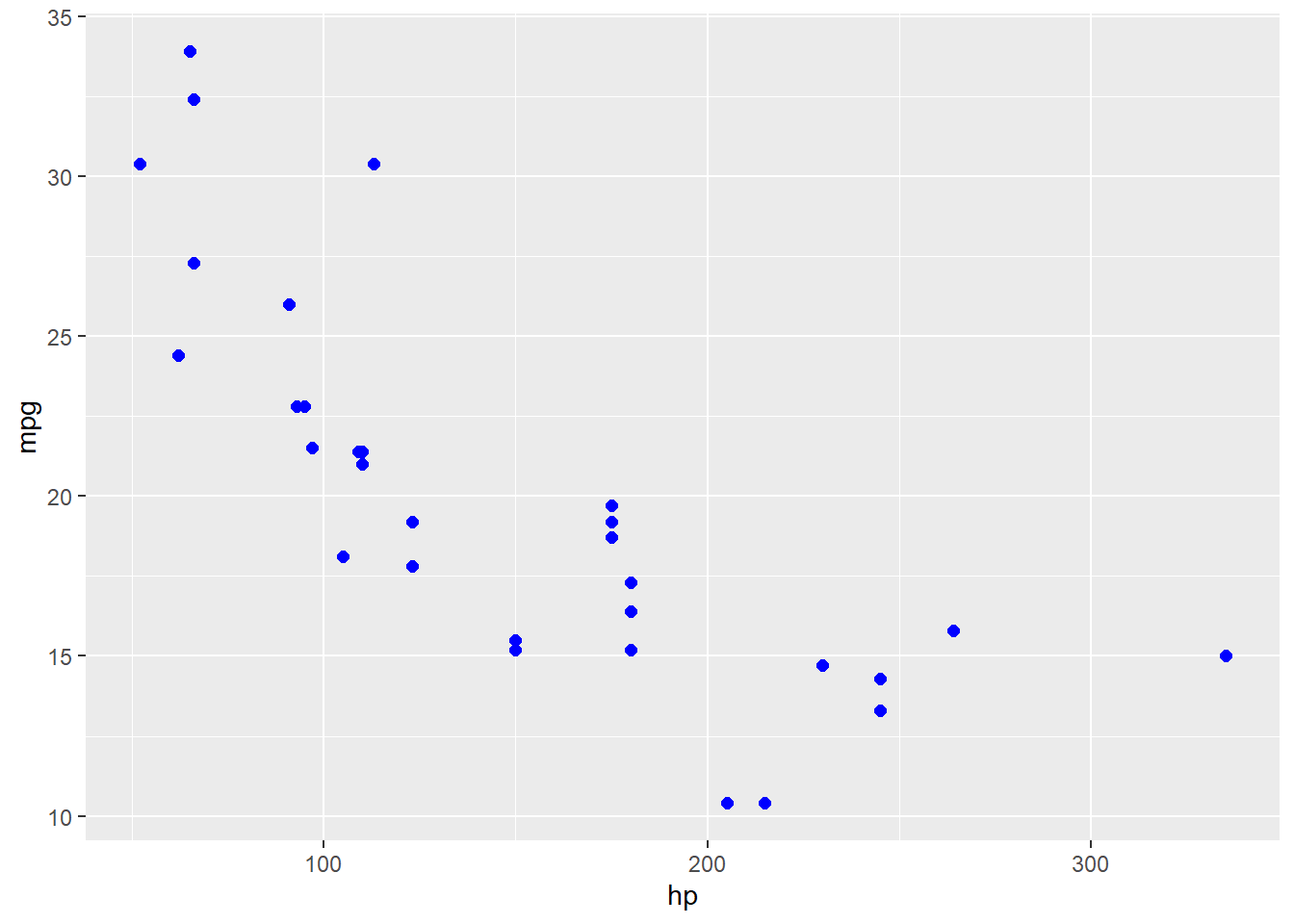
ggplot(data = mtcars, aes(x = hp, y = mpg)) +# Notez l'utilisation du petit "+" ici. geom_point()
Avec geom_point(), nous avons ajouté la géométrie des points (un nuage de points). Maintenant, chaque observation dans nos données est représentée par un point.
3. Personnalisation
ggplot(data = mtcars, aes(x = hp, y = mpg)) +# Pour ajouter chaque "couche" (layer), on ajoute un petit "+" en fin de ligne geom_point(color ="blue", size =3) +# Couche des labels, les étiquettes.labs(title ="Consommation de carburant en fonction de la puissance",x ="Puissance (hp)",y ="Consommation (mpg)") +# Couche pour un thème. Il y en a plein de dispo ! theme_minimal()
Nous avons ici :
Personnalisé les points en ajoutant de la couleur (color = "blue") et une taille (size = 3).
Ajouté un titre et des étiquettes pour les axes avec la fonction labs().
Modifié le style du graphique avec theme_minimal() pour obtenir un rendu plus épuré.
Alors, certes, ce n’est pas le graphique de l’année, mais voyez comme c’est simple !
3. Un principe simple, une puissance infinie
Chaque fois que vous voulez enrichir votre graphique, il vous suffit d’ajouter une couche (layer). C’est aussi simple que ça !
3.1 Exemple plus complexe avec plusieurs couches :
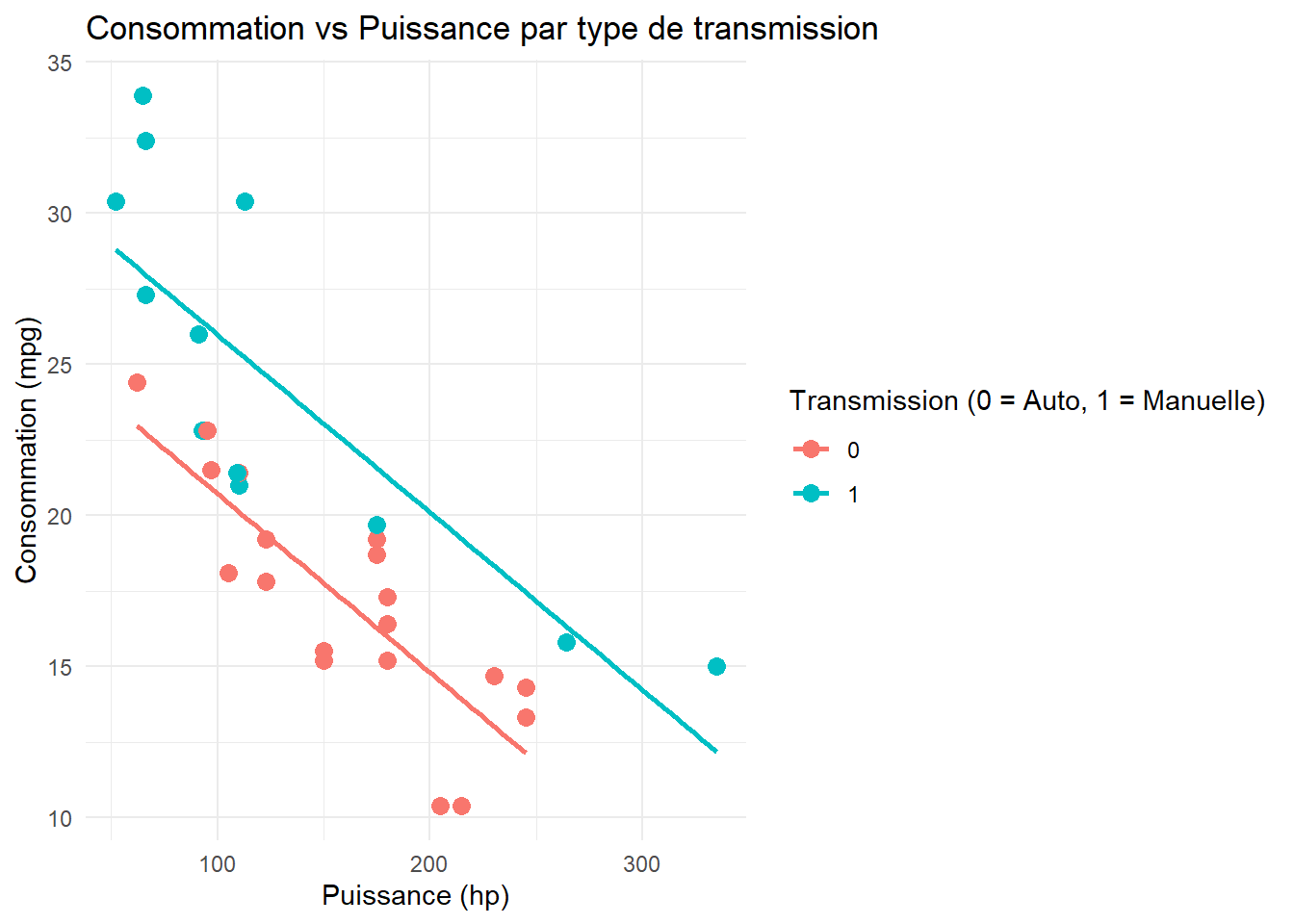
Imaginons que vous vouliez comparer la consommation des voitures par puissance, tout en différenciant les transmissions automatiques et manuelles.
ggplot(data = mtcars, aes(x = hp, y = mpg, color =as.factor(am))) +geom_point(size =3) +# Ajouter des pointsgeom_smooth(method ="lm", se =FALSE) +# Ajouter une ligne de tendancelabs(title ="Consommation vs Puissance par type de transmission",x ="Puissance (hp)",y ="Consommation (mpg)",color ="Transmission (0 = Auto, 1 = Manuelle)") +theme_minimal()
Ici, en plus des points, on a ajouté une ligne de tendance avec geom_smooth() et on a coloré les points selon le type de transmission (color = as.factor(am)).
Ca devient complexe ? C’est normal ! Si vous voulez faire simple, c’est simple, si vous voulez faire complexe, c’est … complexe !
Voici une fiche récapitulative qui vous aidera à explorer toutes les possibilités :)
Cheatsheet de GGplot2 !
3.2 Récapitulatif
Commencez avec les données : Vous spécifiez ce que vous voulez visualiser (axe X, Y, couleurs, etc.).
Ajoutez une géométrie : Choisissez la façon dont vous voulez représenter ces données (points, lignes, barres, etc.).
Personnalisez : Ajoutez des couleurs, des tailles, des titres et un style pour rendre le graphique plus lisible et esthétiquement agréable.
GGplot2 est flexible : une fois que vous avez compris ce modèle en couches, vous pouvez tout faire, du graphique simple aux visualisations les plus sophistiquées. Le secret ? Construire chaque graphique comme une phrase avec des composants bien organisés, et y ajouter des détails au fur et à mesure.
IV) Esquisse : Le petit prince de la data viz’
Esquisse est un package R qui permet de créer des graphiques de manière interactive avec une interface glisser-déposer, sans avoir à écrire du code GGplot2. Il est particulièrement utile pour les débutants ou pour ceux qui veulent rapidement visualiser leurs données sans se plonger dans les détails de GGplot.
Pourquoi utiliser Esquisse ?
Apprentissage progressif : Pour un débutant, Esquisse permet de comprendre les bases de la visualisation en R sans passer par le code immédiatement. Vous pouvez créer des graphiques simplement en choisissant vos variables, puis observer le code GGplot2 généré automatiquement. C’est un excellent point de départ pour apprendre à construire des graphiques plus complexes.
Gain de temps : Si vous avez besoin d’une visualisation rapide, Esquisse vous permet de tester différentes options (types de graphiques, couleurs, esthétiques) en quelques clics, sans taper une ligne de code. Vous obtenez un rendu instantané qui vous aide à explorer vos données rapidement.
Exploration des données facile : Le glisser-déposer rend l’exploration des données intuitive. Vous pouvez tester plusieurs combinaisons de variables (par exemple, voir l’impact d’une variable catégorielle ou continue sur une autre) et ajuster vos graphiques à la volée.
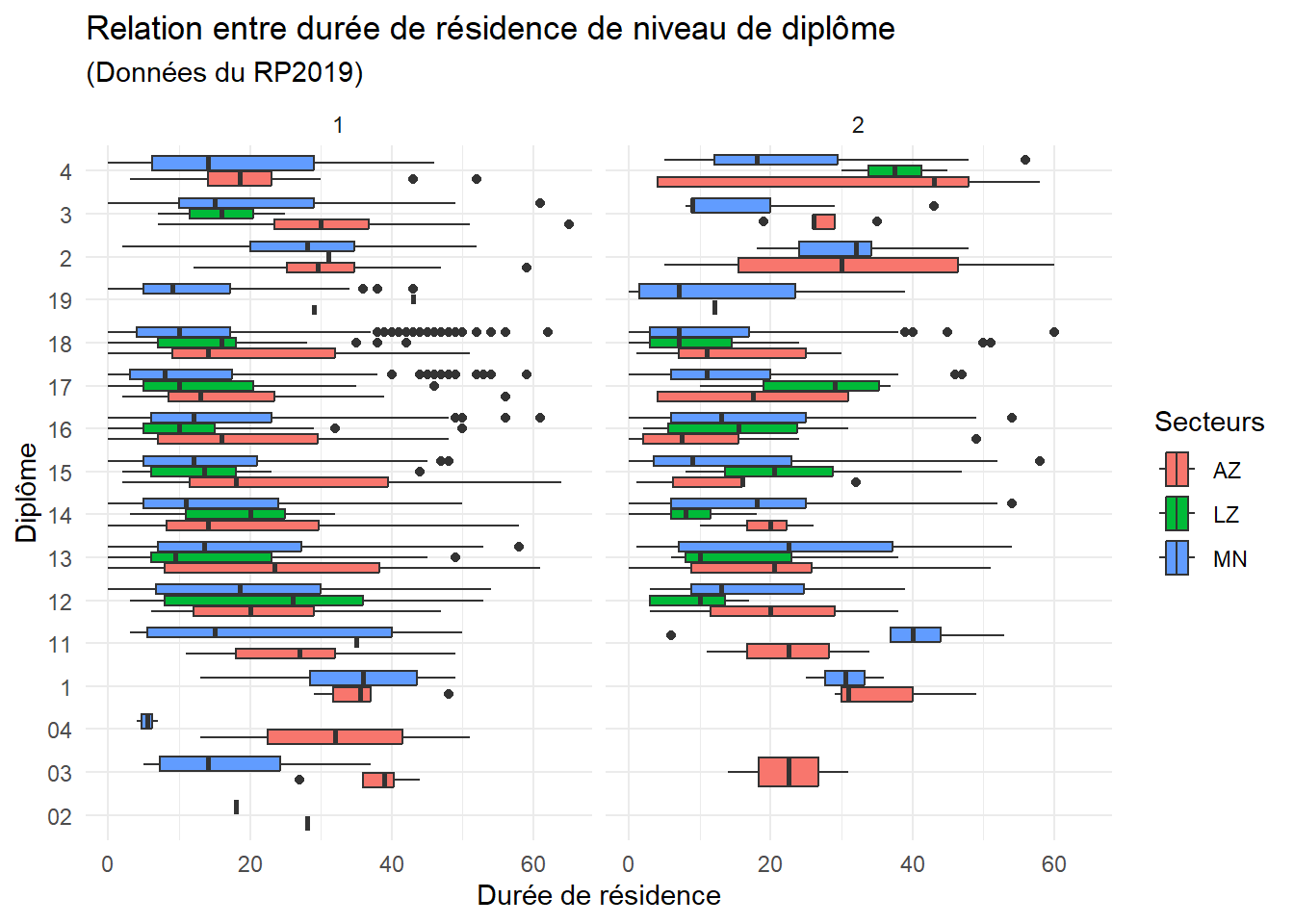
Voila un exemple en 10 captures d’écrans !
On commence par faire :
esquisse::esquisser()
Et ensuite c’est parti !
RP2019NC_OD_ind_3Provinces %>% dplyr::filter(!is.na(DIPL)) %>% dplyr::filter(SECT10 %in%c("AZ", "LZ", "MN")) %>% dplyr::filter(!is.na(duree_residence)) %>%ggplot() +aes(x = duree_residence, y = DIPL, fill = SECT10) +geom_boxplot() +scale_fill_hue(direction =1) +labs(x ="Durée de résidence",y ="Diplôme",title ="Relation entre durée de résidence de niveau de diplôme",subtitle ="(Données du RP2019)",fill ="Secteurs" ) +theme_minimal() +facet_wrap(vars(COUPLE))
V) Les fonctions utiles de GGPLOT et comment les utiliser
1. ggplot() : La base
Description : C’est le point de départ. Tu y spécifies les données et les esthétiques (axes, couleurs, etc.).
ggplot(data = mtcars, aes(x = hp, y = mpg)) # hp sur l'axe X, mpg sur l'axe Y
Astuce : Rien ne s’affichera tant que tu n’ajouteras pas une géométrie (geom).
2. geom_point() : Nuage de points
Description : Affiche des points pour visualiser la relation entre deux variables continues.
Astuce : Idéal pour visualiser la corrélation entre deux variables. Change la taille ou la couleur des points avec size et color.
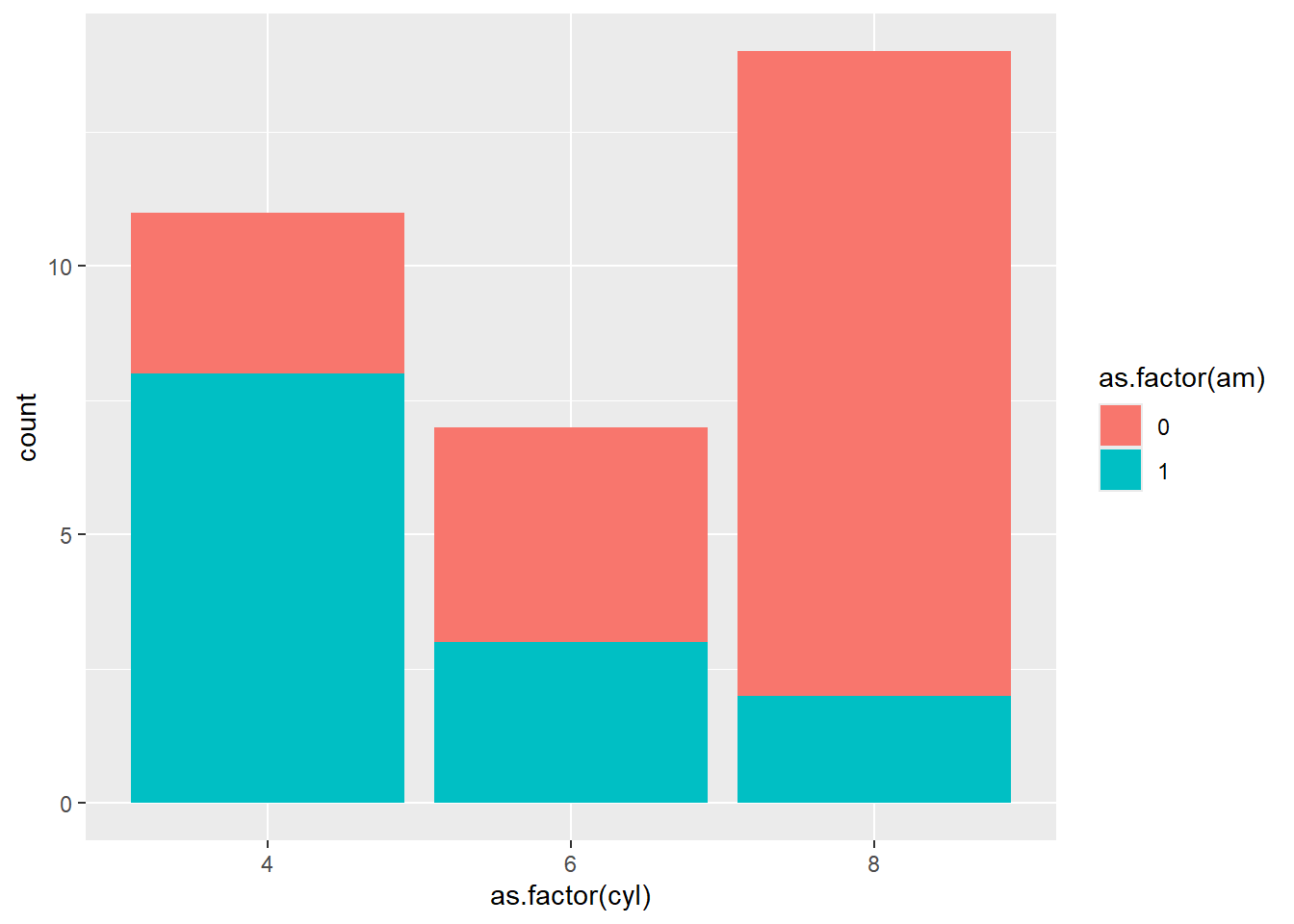
3. geom_bar() : Diagramme en barres
Description : Parfait pour comparer des catégories ou afficher des fréquences.
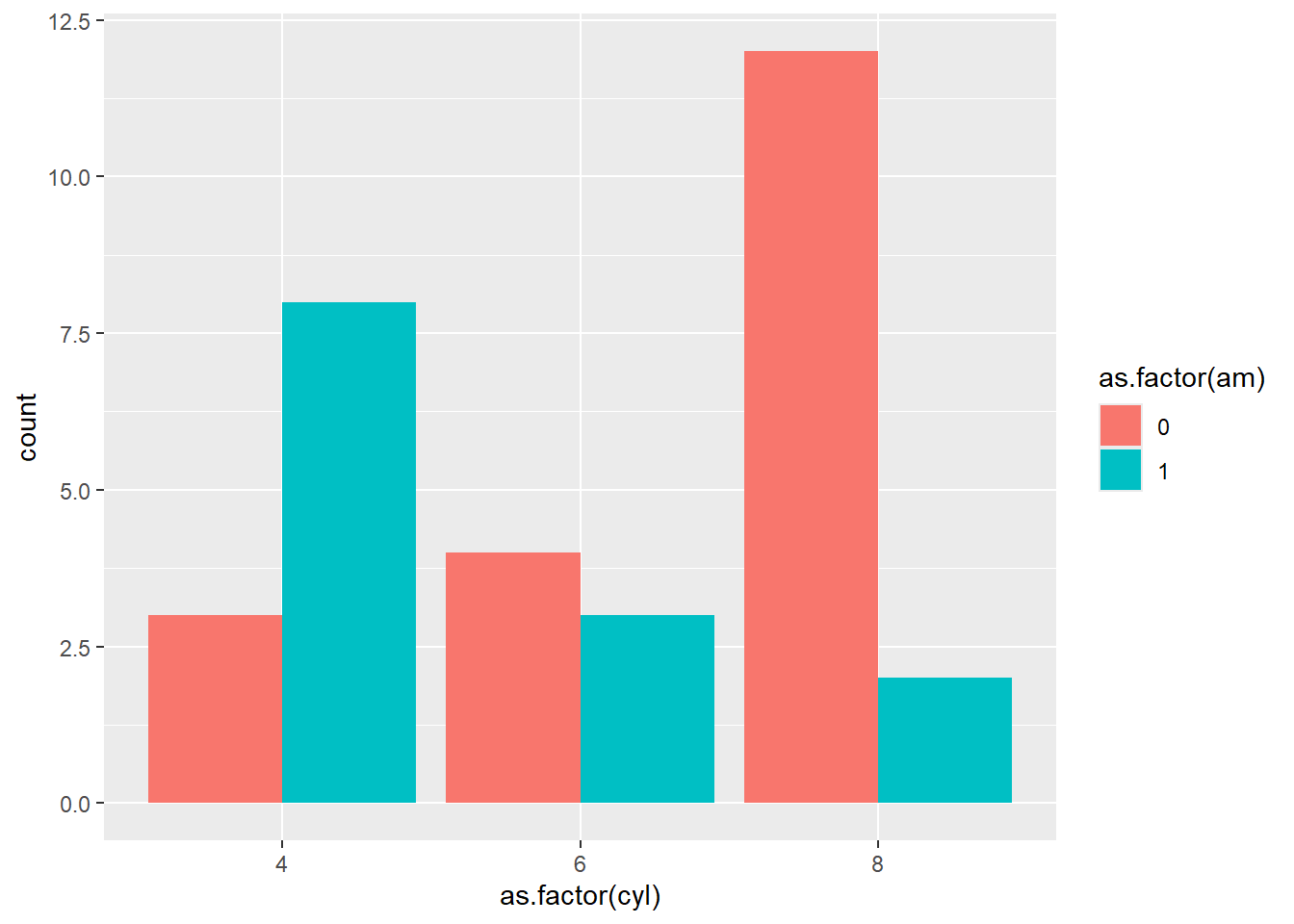
ggplot(data = mtcars, aes(x =as.factor(cyl), fill =as.factor(am))) +geom_bar()
Astuce : Attention, si tu veux comparer plusieurs catégories, utilise position = "dodge" pour éviter les barres empilées.
ggplot(data = mtcars, aes(x =as.factor(cyl), fill =as.factor(am))) +geom_bar(position ="dodge")
4. geom_histogram() : Histogramme
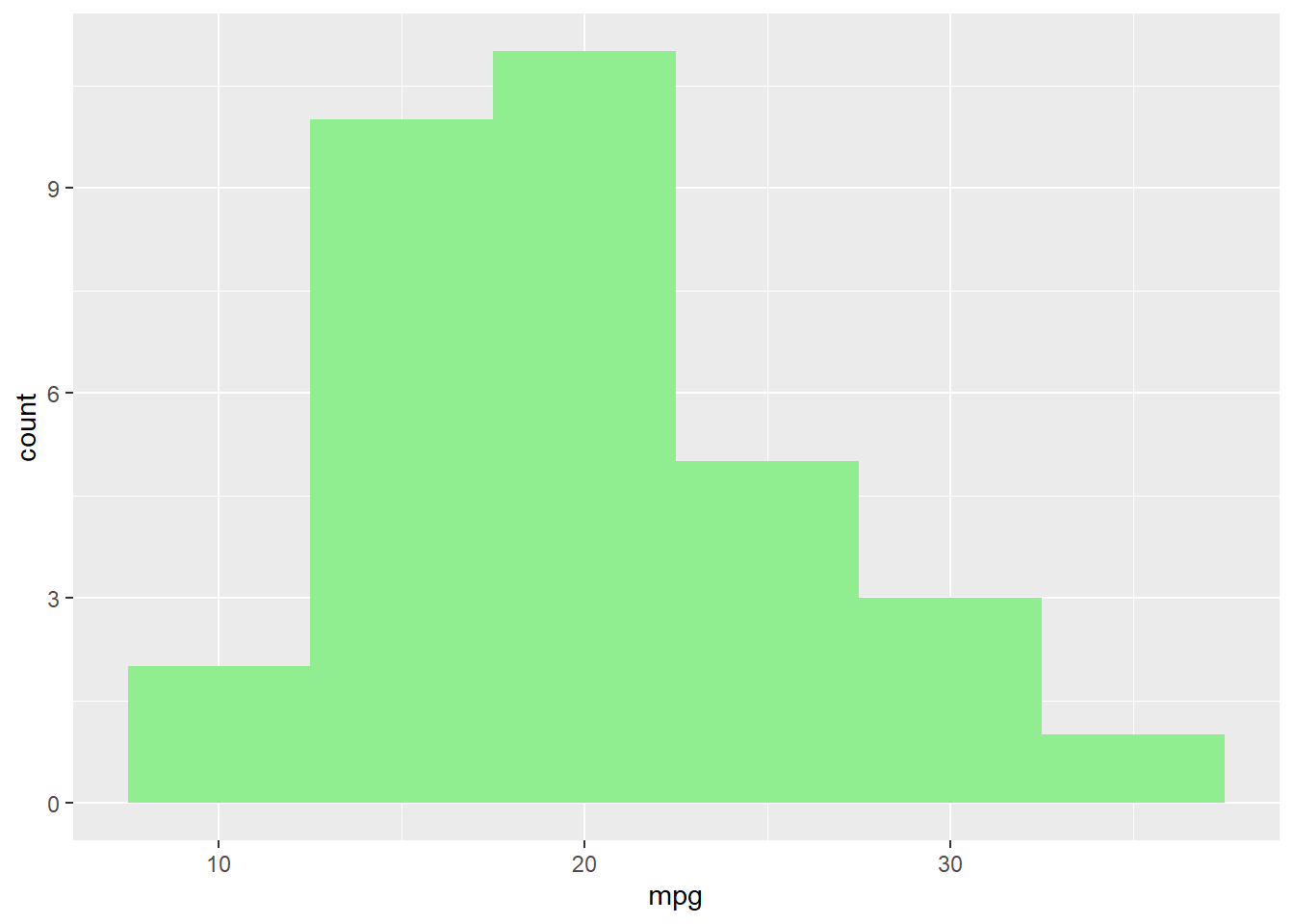
Description : Utile pour visualiser la distribution d’une variable continue.
ggplot(data = mtcars, aes(x = mpg)) +geom_histogram(binwidth =5, fill ="lightgreen")
Astuce : Joue avec binwidth pour ajuster la taille des barres. Cela te permet de mieux visualiser la répartition des données.
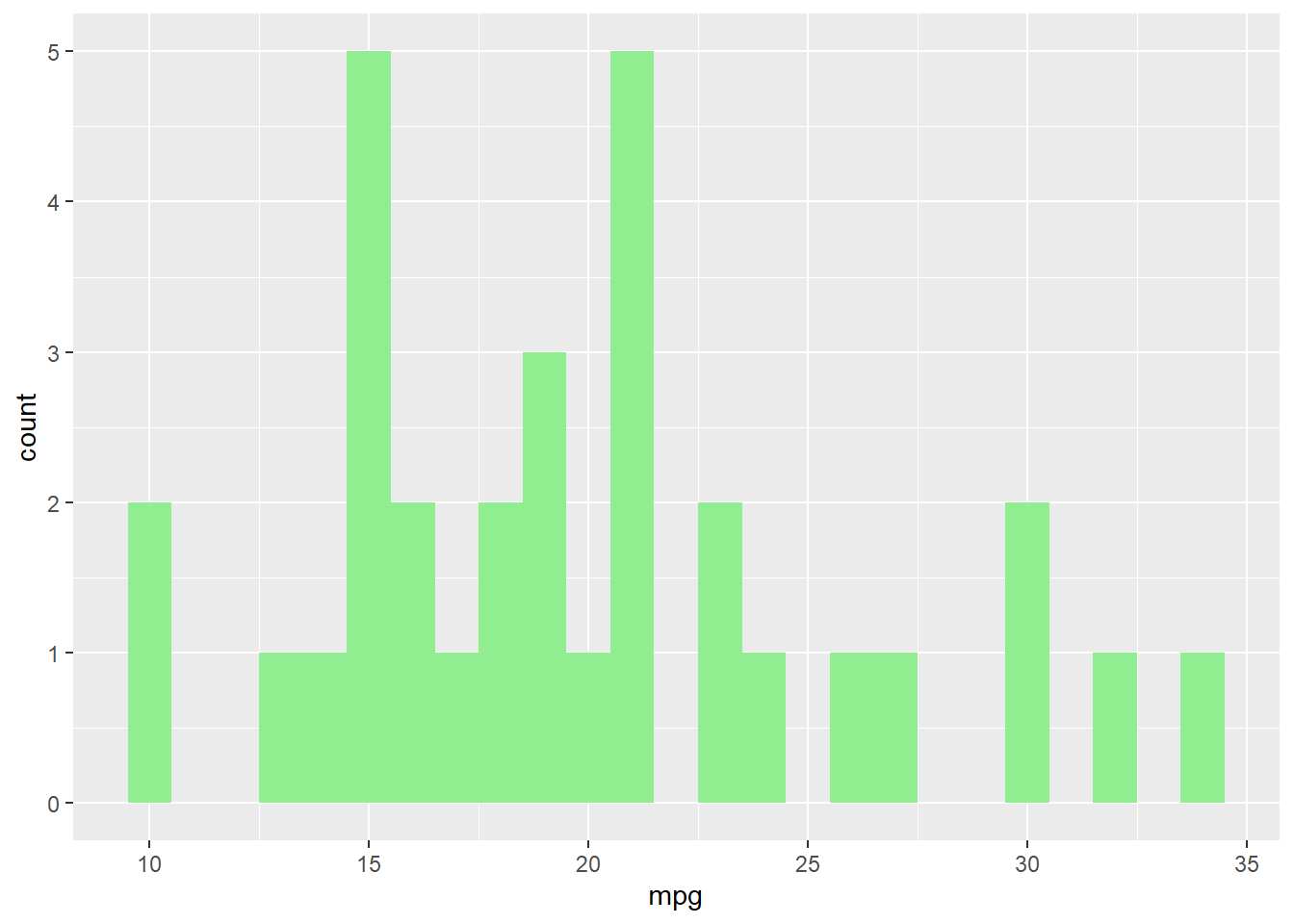
ggplot(data = mtcars, aes(x = mpg)) +geom_histogram(binwidth =1, fill ="lightgreen")
Pour calculer le meilleur nombre de bins dans un histogramme, on utilise souvent la règle de Sturges ou la règle de Freedman-Diaconis. Ces méthodes ajustent le nombre de bins en fonction de la taille de l’échantillon et de la distribution des données, afin d’optimiser la lisibilité.
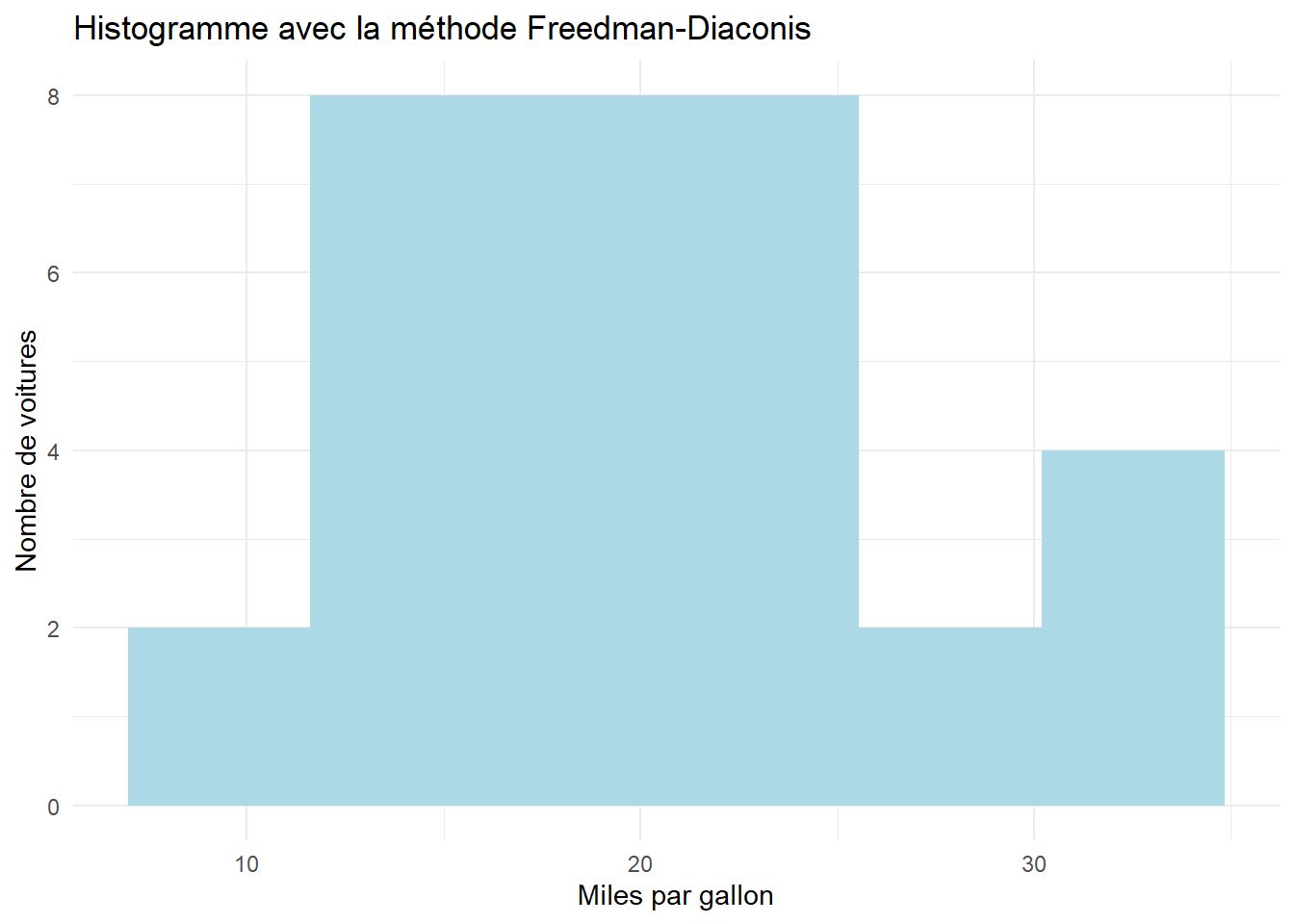
Méthode de Freedman-Diaconis :
Elle ajuste la largeur des bins en tenant compte de l’écart interquartile (IQR) des données et de leur taille. Elle est plus précise pour des distributions non normales. Voici comment calculer le binwidth en utilisant la règle de Freedman-Diaconis :
# Calcul de l'IQR (écart interquartile) et de la taille de l'échantilloniqr_mpg <-IQR(mtcars$mpg)n <-length(mtcars$mpg)# Calcul de la largeur des bins selon la règle de Freedman-Diaconisbinwidth_fd <-2* iqr_mpg / (n^(1/3))# Utilisation du binwidth calculé dans l'histogrammeggplot(data = mtcars, aes(x = mpg)) +geom_histogram(binwidth = binwidth_fd, fill ="lightblue") +labs(title ="Histogramme avec la méthode Freedman-Diaconis",x ="Miles par gallon",y ="Nombre de voitures") +theme_minimal()
Explication :
IQR : Écart interquartile, qui mesure la dispersion des données.
n : Taille de l’échantillon.
binwidth_fd : Largeur des bins calculée en fonction de la règle de Freedman-Diaconis.
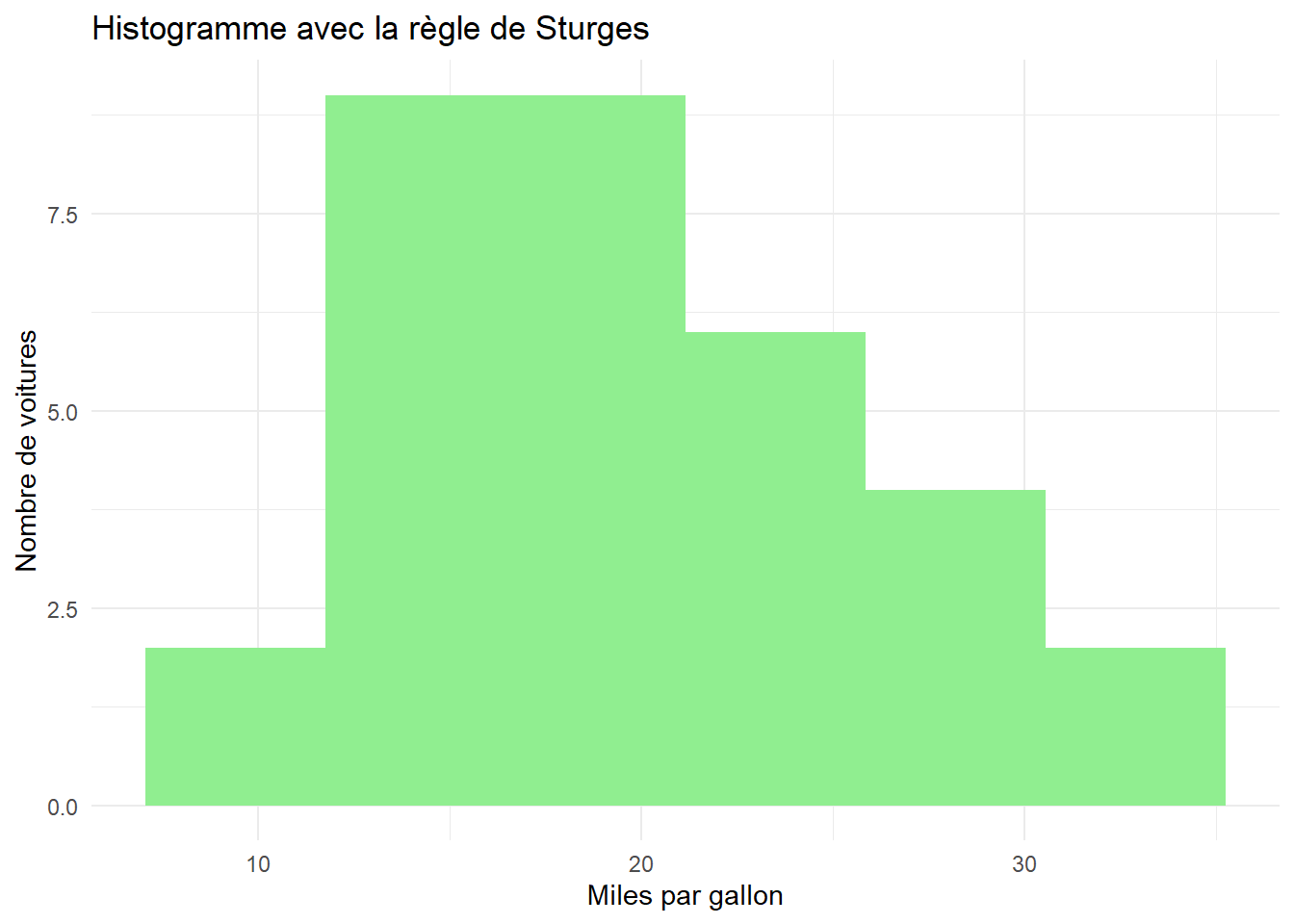
Méthode de Sturges :
La règle de Sturges est une autre méthode populaire pour déterminer le nombre optimal de bins dans un histogramme. Elle est plus simple que la méthode de Freedman-Diaconis et est particulièrement adaptée à des échantillons de taille modérée.
Contrairement à Freedman-Diaconis, qui ajuste la largeur des bins, Sturges ajuste directement le nombre de bins. Voici comment tu peux l’utiliser dans GGplot :
# Calcul du nombre de bins avec la règle de Sturgesn <-length(mtcars$mpg)num_bins_sturges <-ceiling(log2(n) +1)# Utilisation du nombre de bins dans l'histogrammeggplot(data = mtcars, aes(x = mpg)) +geom_histogram(bins = num_bins_sturges, fill ="lightgreen") +labs(title ="Histogramme avec la règle de Sturges",x ="Miles par gallon",y ="Nombre de voitures") +theme_minimal()
Explication :
n : Taille de l’échantillon.
num_bins_sturges : Nombre optimal de bins calculé selon la règle de Sturges.
bins : Dans GGplot2, on utilise bins pour définir le nombre de divisions dans l’histogramme (contrairement à binwidth qui ajuste la largeur des bins).
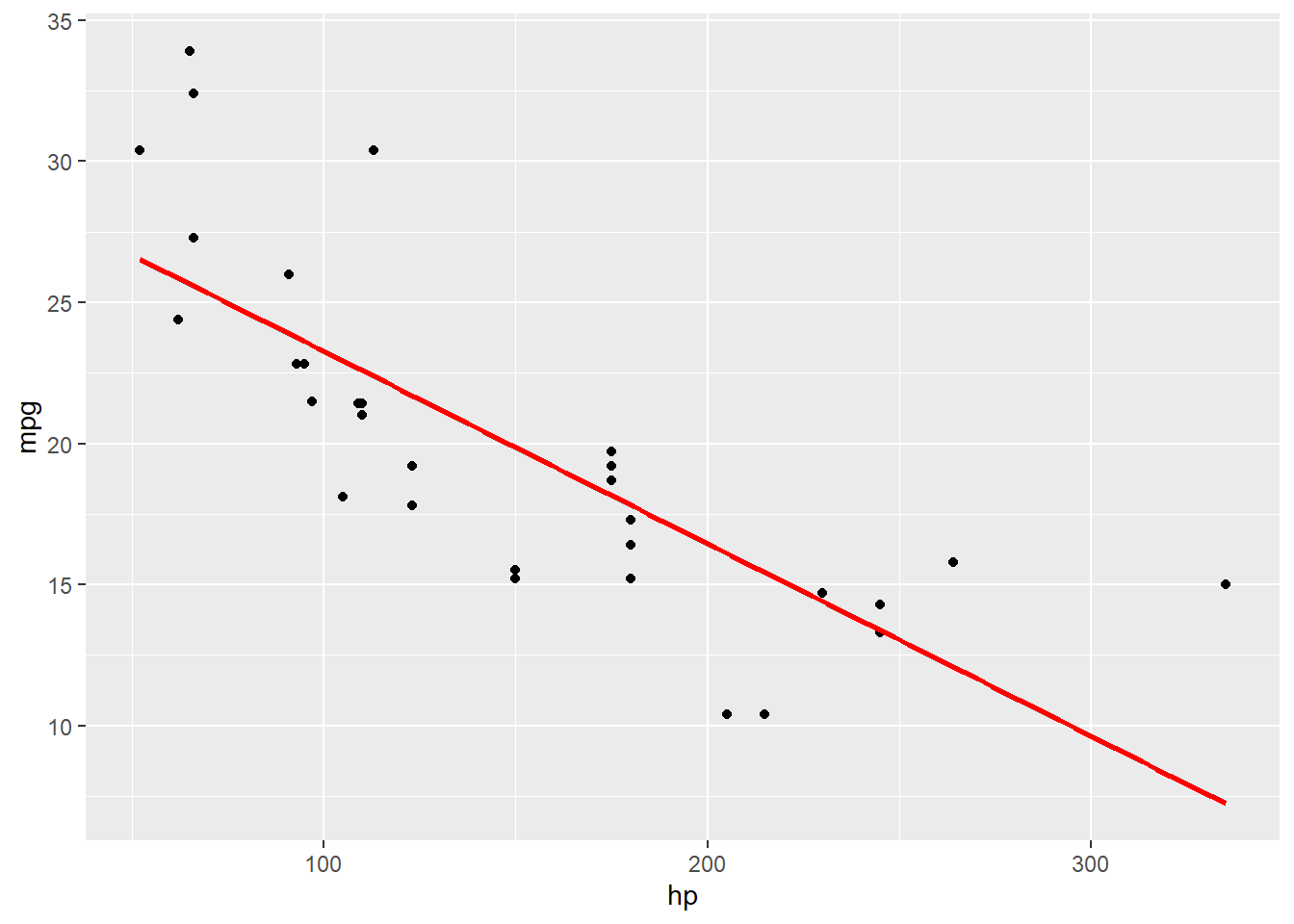
5. geom_smooth() : Ligne de tendance
Description : Ajoute une ligne de tendance, souvent utilisée avec des nuages de points.
ggplot(data = mtcars, aes(x = hp, y = mpg)) +geom_point() +geom_smooth(method ="lm", se =FALSE, color ="red")
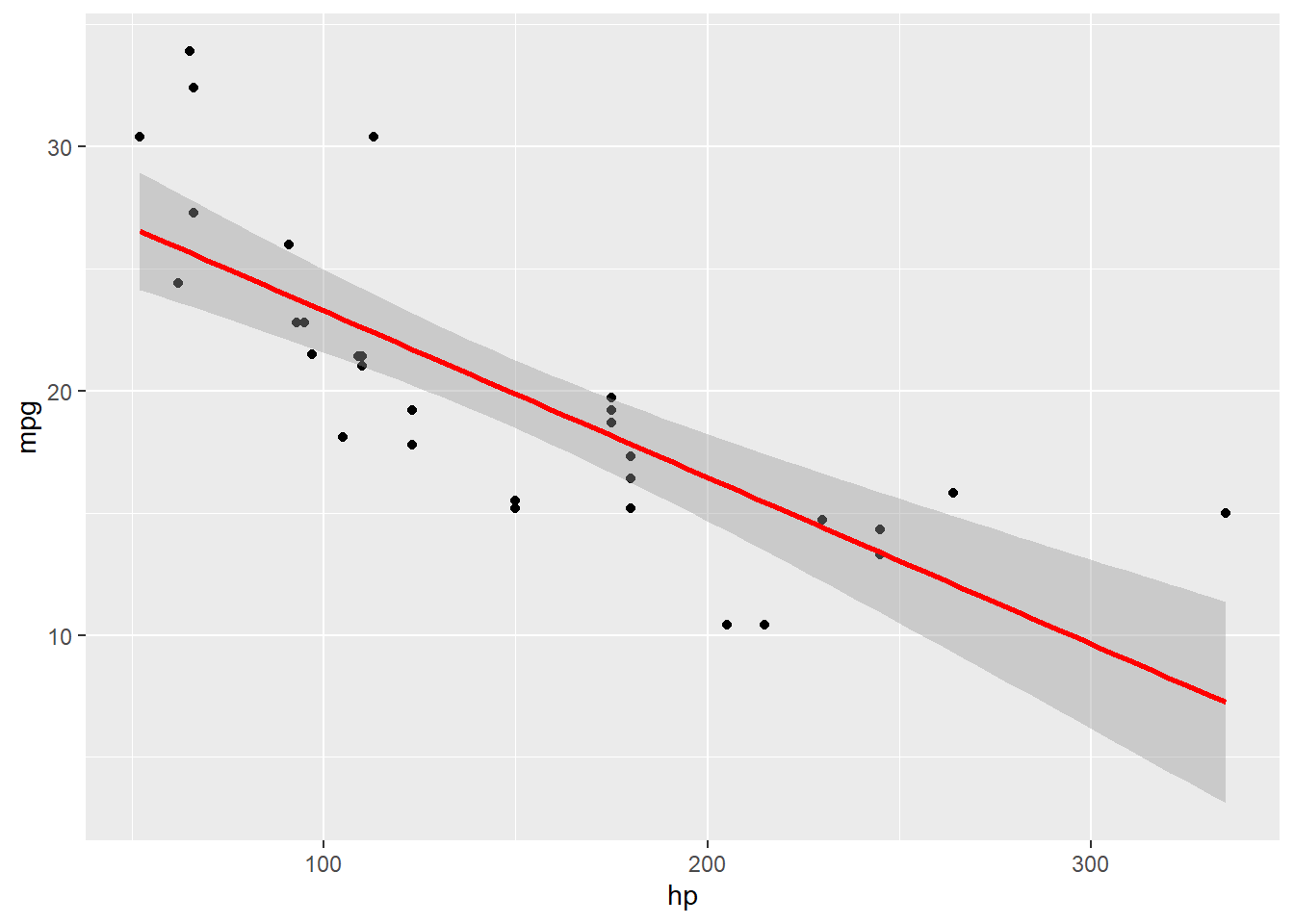
Astuce : Utilise method = "lm" pour une régression linéaire, et enlève l’intervalle de confiance avec se = FALSE si tu veux une ligne plus simple. Avec se = TRUE cela donne :
ggplot(data = mtcars, aes(x = hp, y = mpg)) +geom_point() +geom_smooth(method ="lm", se =TRUE, color ="red")
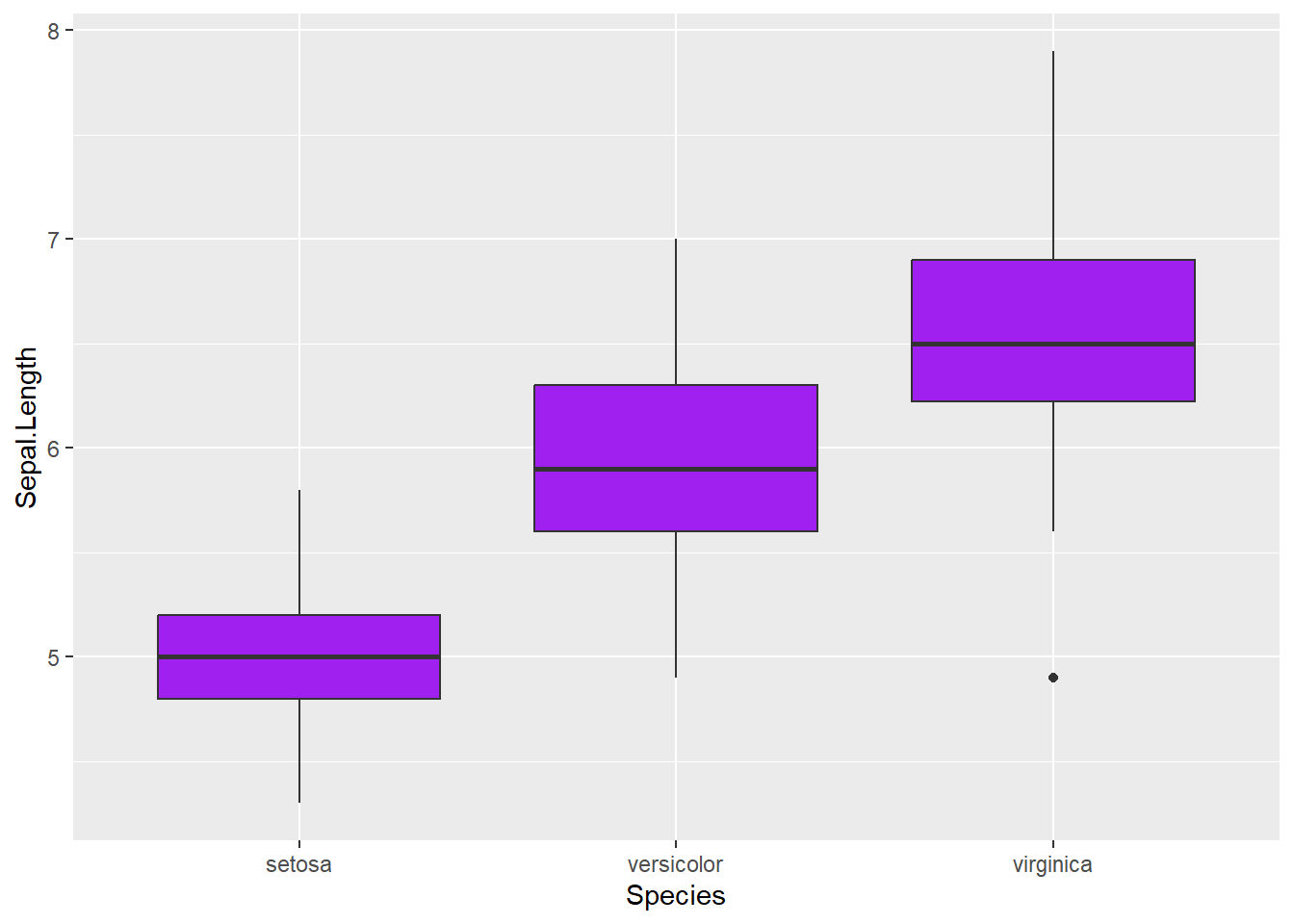
6. geom_boxplot() : Boxplot
Description : Visualise la distribution d’une variable continue avec des quartiles et des valeurs extrêmes.
Astuce : Super utile pour comparer la dispersion de plusieurs groupes (ici, les espèces de fleurs).
Zoom sur le “Boxplot” : Simplicité et comparaison rapide
Quand utiliser ?
Si tu veux un aperçu rapide de la distribution : Le boxplot est parfait pour afficher les informations essentielles sur une distribution de données : la médiane, les quartiles, et les éventuelles valeurs aberrantes (outliers). Si tu cherches une représentation simple et compacte, c’est la meilleure option.
Pour comparer plusieurs groupes : Le boxplot est idéal pour comparer des groupes côte à côte (ex. comparer la distribution de la longueur des pétales entre plusieurs espèces de fleurs dans le jeu de données iris).
Pour les audiences non techniques : Le boxplot est facile à comprendre même pour des personnes qui ne sont pas très à l’aise avec les statistiques. Il montre clairement la dispersion des données et les éventuelles valeurs aberrantes sans entrer dans les détails.
ggplot(data = iris, aes(x = Species, y = Sepal.Length)) +geom_boxplot(fill ="lightblue") +labs(title ="Boxplot : Longueur des sépales par espèce",x ="Espèce",y ="Longueur des sépales")
Ce qu’il montre :
La médiane : La ligne horizontale au centre de la boîte.
Les quartiles : La boîte représente l’intervalle entre le 1er et le 3e quartile (50 % des données).
Les valeurs aberrantes : Les points en dehors des “moustaches” sont des valeurs atypiques (les fameux “outliers”).
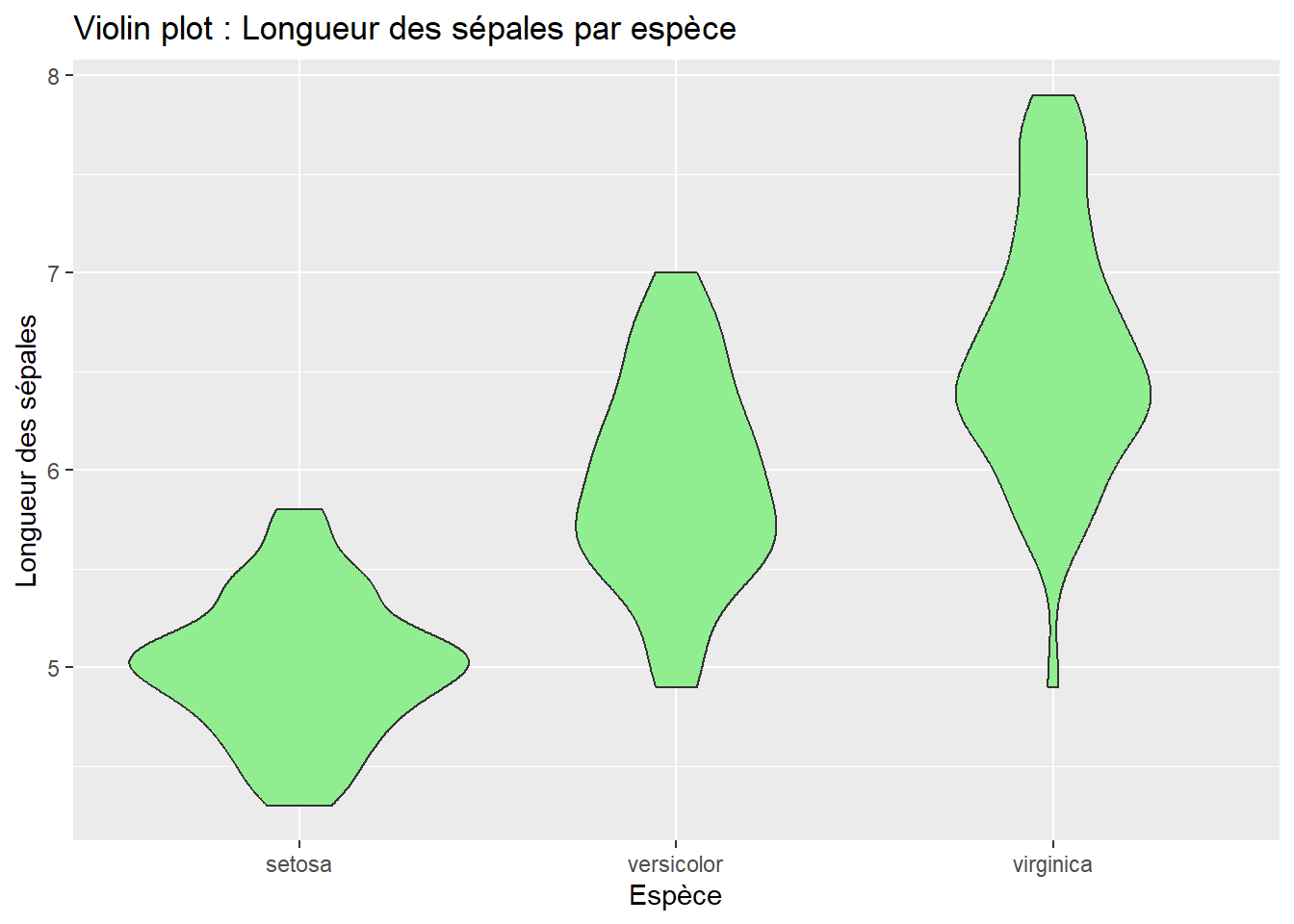
7. geom_violin() : Violin plot
Description : Une alternative au boxplot, il montre la distribution des données et leur densité.
Astuce : Utilise ce type de graphique pour des distributions complexes et asymétriques.
Zoom sur le “Violin plot” : Détails sur la distribution et la densité
Quand utiliser ?
Si tu veux montrer la densité des données : Le violin plot est en fait un boxplot amélioré. Il inclut les mêmes informations (médiane, quartiles, etc.), mais il te montre également la forme complète de la distribution. La largeur du violon indique la densité des données à différents niveaux de la variable.
Pour des distributions complexes ou asymétriques : Si tu as une distribution bimodale ou asymétrique, un violin plot le révélera beaucoup mieux qu’un boxplot. C’est un bon choix si tu veux montrer où les données sont concentrées.
Pour les audiences plus techniques : Un violin plot est un peu plus complexe à lire. Il est donc plus adapté à des publics familiers avec les concepts statistiques de distribution et de densité.
ggplot(data = iris, aes(x = Species, y = Sepal.Length)) +geom_violin(fill ="lightgreen") +labs(title ="Violin plot : Longueur des sépales par espèce",x ="Espèce",y ="Longueur des sépales")
Ce qu’il montre :
La densité des données : La largeur du “violon” indique la concentration des données. Si le violon est plus large à certains endroits, cela signifie qu’il y a plus de données dans cette plage de valeurs.
Les modes de distribution : Un violin plot montre si les données ont une distribution bimodale (deux pics), ce qu’un boxplot ne peut pas afficher.
Les mêmes informations qu’un boxplot : Il inclut également les médianes et les quartiles, donc tu ne perds pas les informations essentielles du boxplot.
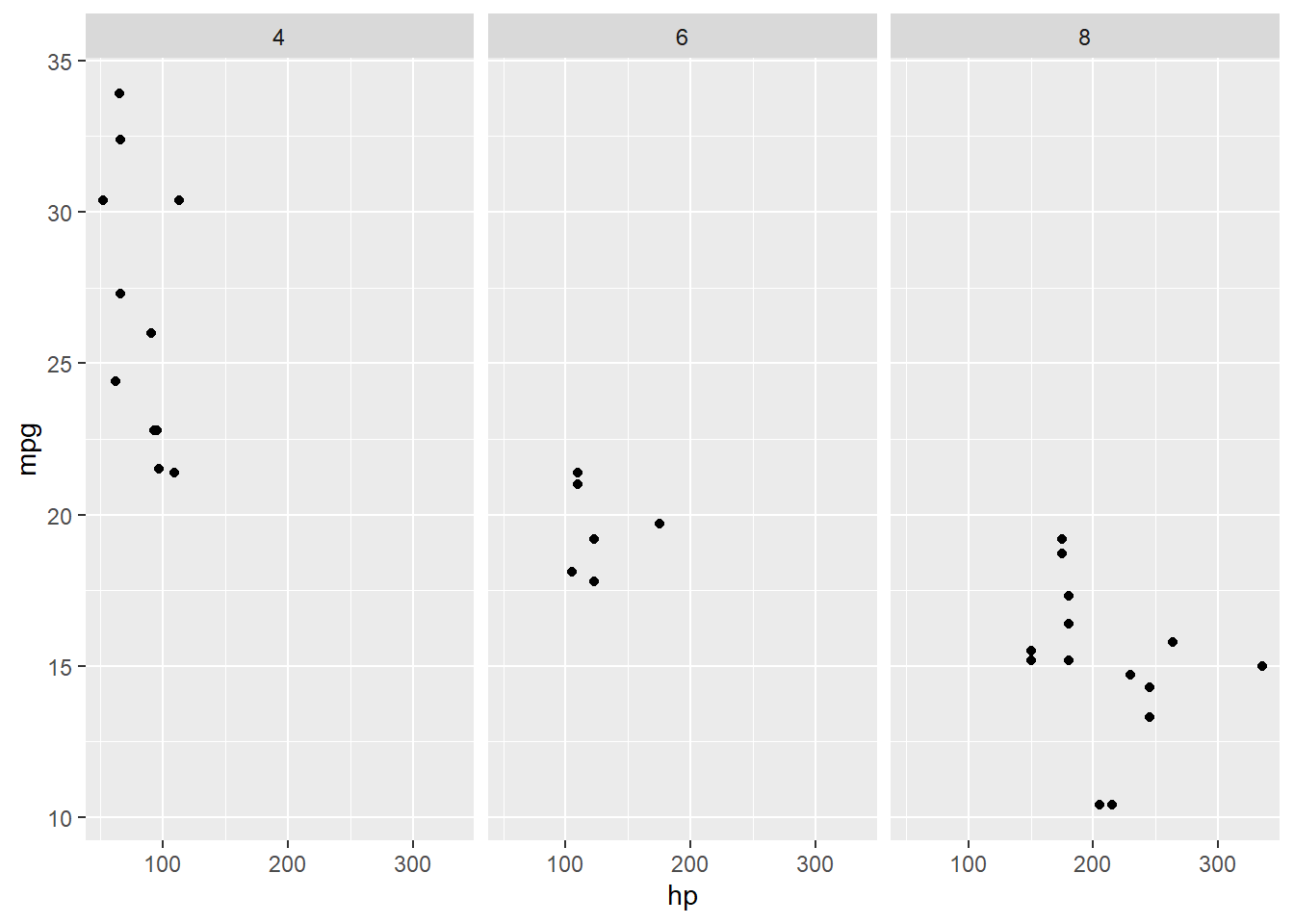
8. facet_wrap() : Diviser le graphique en plusieurs sous-graphes
Description : Crée plusieurs graphiques à partir d’une variable catégorielle.
Astuce : Facile pour comparer les relations entre différentes catégories (ici les cylindres de voiture).
9. aes() : Définir les esthétiques (axes, couleurs, tailles, etc.)
Description : Spécifie les variables à utiliser pour les axes X et Y, ainsi que pour la couleur, la taille, etc.
ggplot(data = mtcars, aes(x = hp, y = mpg, color =as.factor(cyl))) +geom_point()
Astuce : L’esthétique color est super pour ajouter une dimension supplémentaire à ton graphique, en visualisant une troisième variable (ici, cyl).
Zoom sur “aes” : La base des esthétiques dans GGplot2
Voyons maintenant quelques variations et combinaisons de ce que tu peux faire avec aes() pour enrichir et personnaliser tes graphiques.
1. Changer la couleur selon une variable catégorielle
Tu peux colorer les points ou barres en fonction d’une variable. Ici, on utilise as.factor() pour convertir la variable cyl (nombre de cylindres) en catégorie, afin d’avoir des couleurs différentes pour chaque groupe.
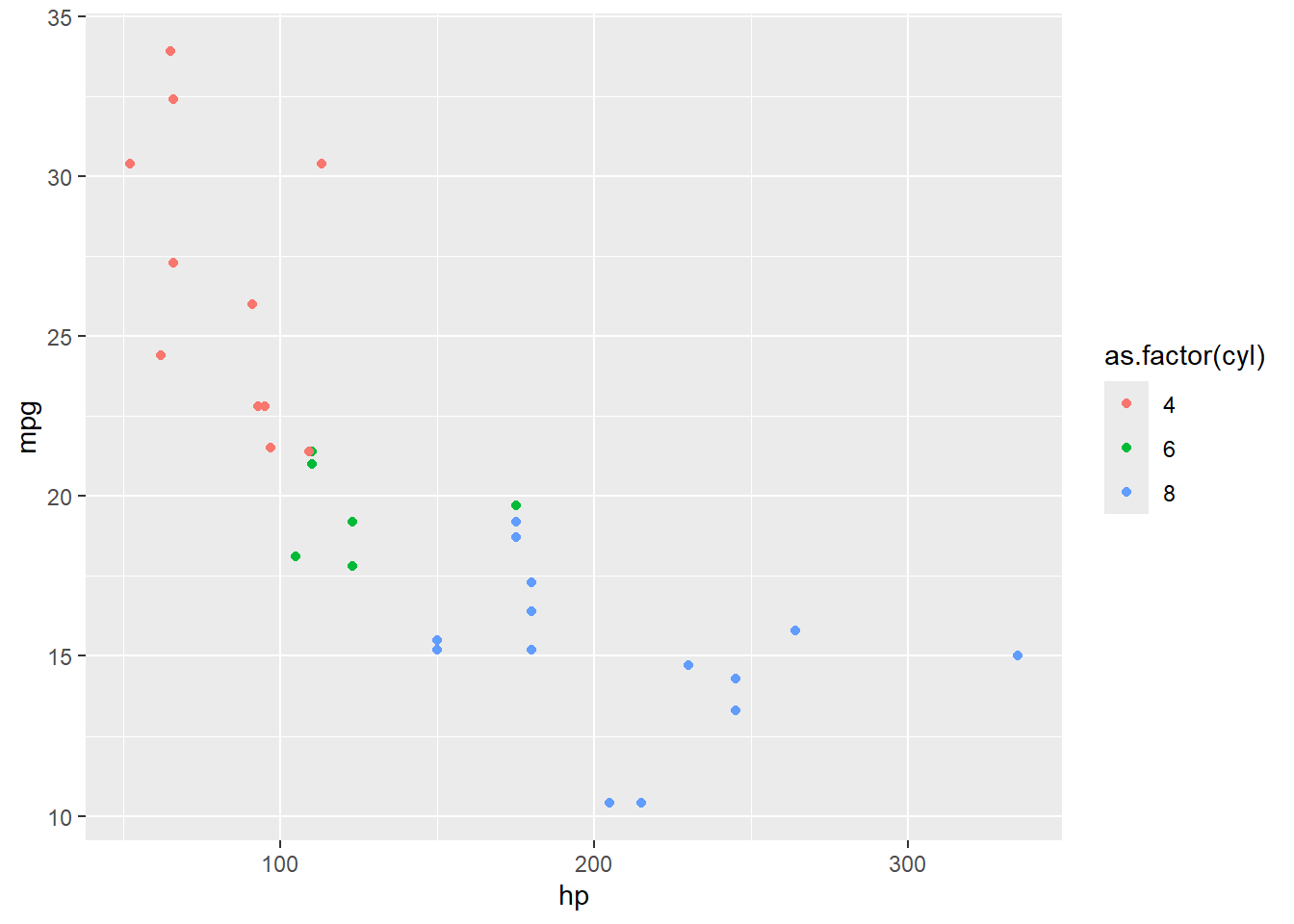
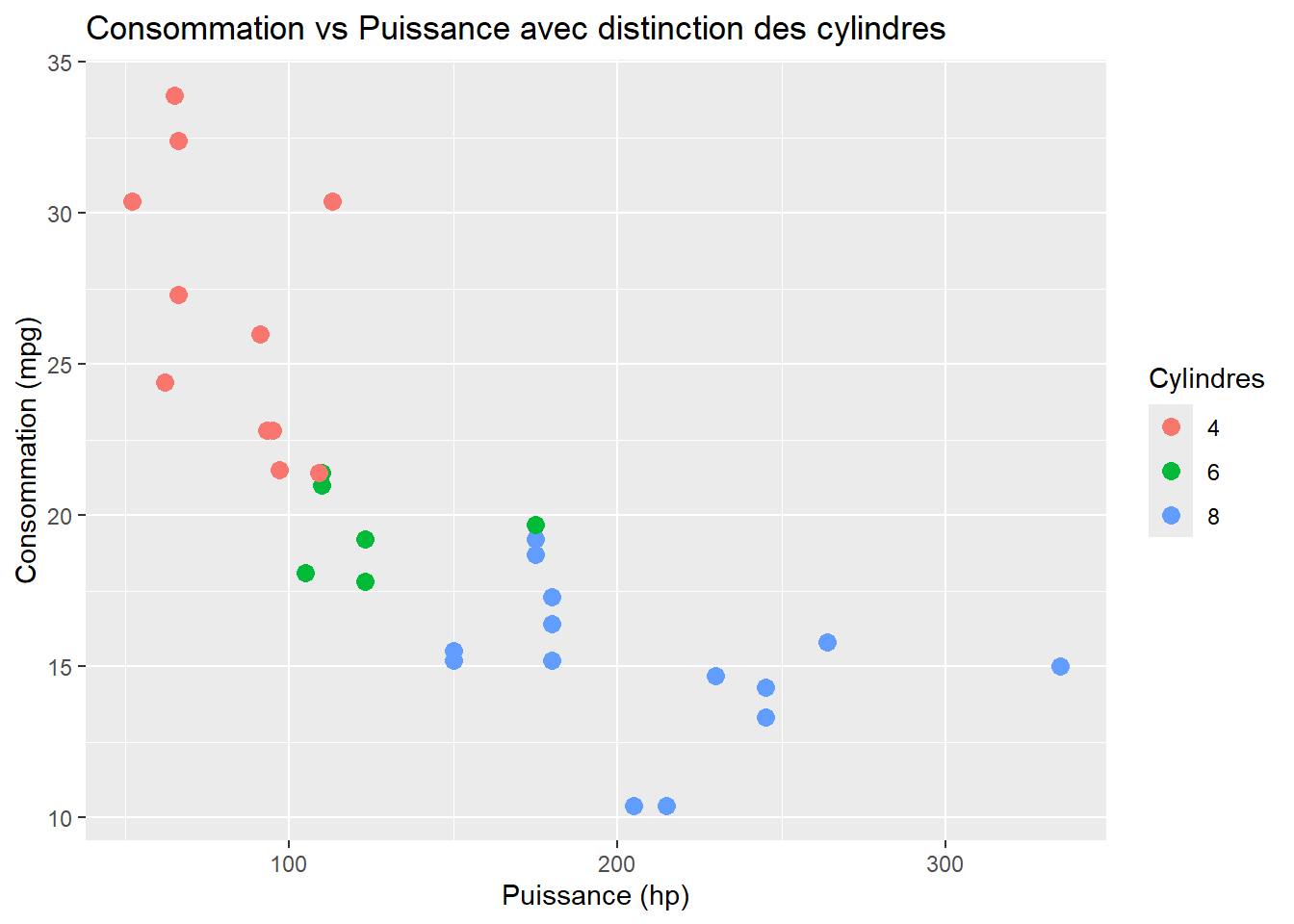
ggplot(data = mtcars, aes(x = hp, y = mpg, color =as.factor(cyl))) +geom_point(size =3) +labs(title ="Consommation vs Puissance avec distinction des cylindres",x ="Puissance (hp)",y ="Consommation (mpg)",color ="Cylindres")
Astuce : Utiliser color avec une variable catégorielle est super pratique pour ajouter une dimension supplémentaire à ton graphique (ici, cyl). Cela te permet de mieux comprendre comment les différentes catégories se comportent vis-à-vis des variables continues.
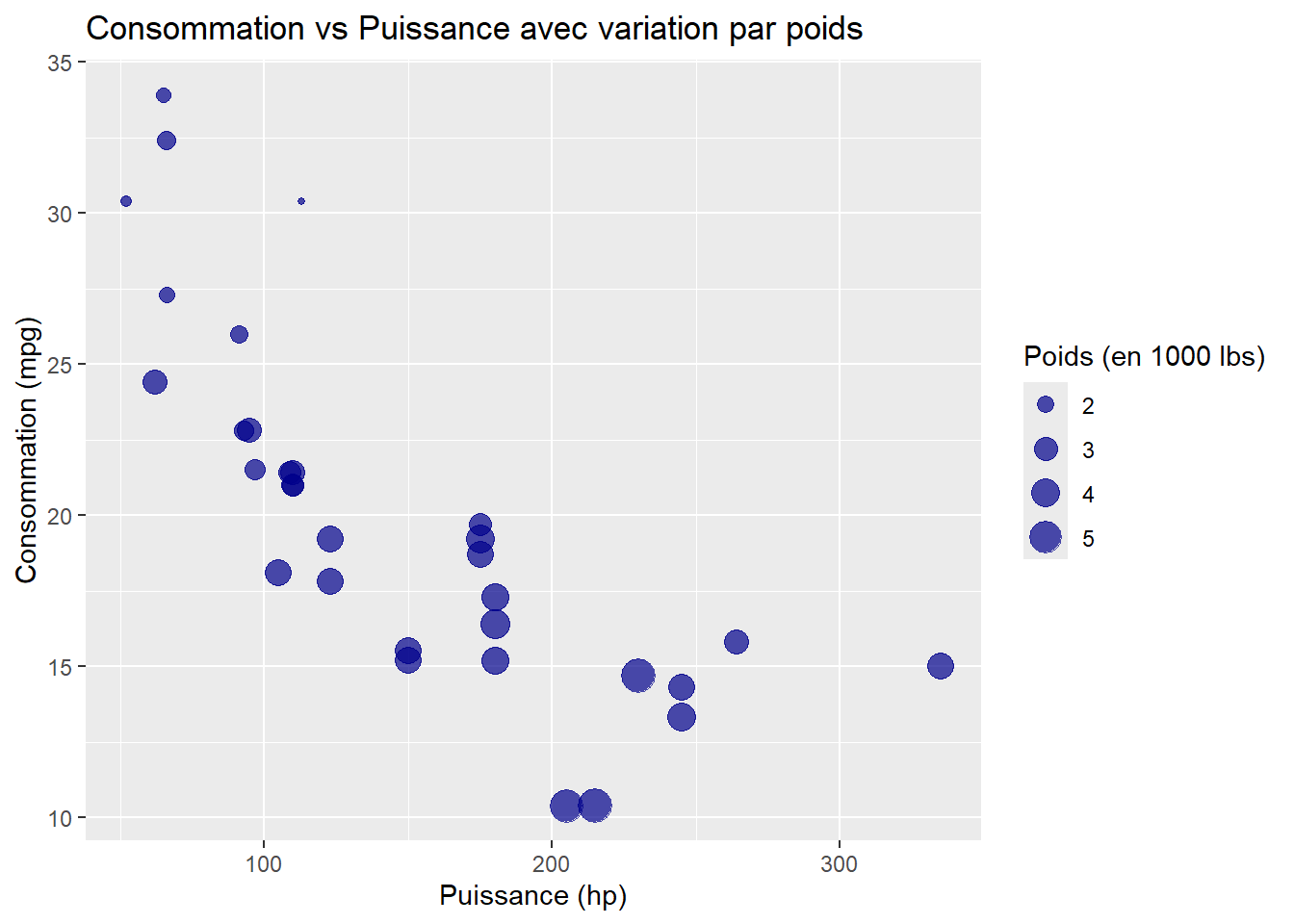
2. Changer la taille des points selon une variable continue
Il est aussi possible de varier la taille des points selon une autre variable continue, ici wt (le poids de la voiture).
ggplot(data = mtcars, aes(x = hp, y = mpg, size = wt)) +geom_point(color ="darkblue", alpha =0.7) +labs(title ="Consommation vs Puissance avec variation par poids",x ="Puissance (hp)",y ="Consommation (mpg)",size ="Poids (en 1000 lbs)")
Astuce : L’utilisation de size est idéale si tu veux ajouter une troisième variable continue à ton graphique. Cela aide à visualiser plusieurs relations à la fois.
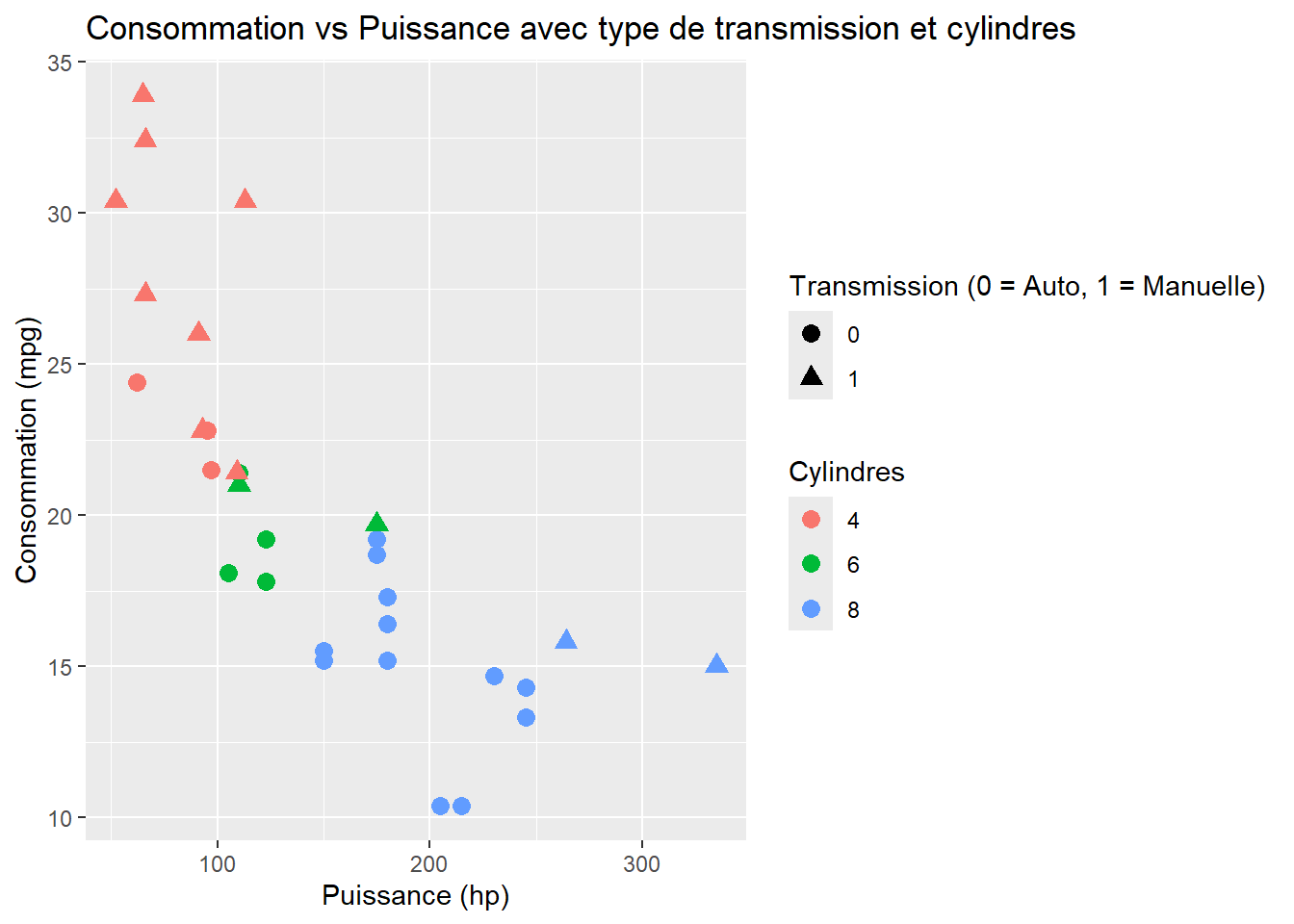
3. Combiner couleur et forme avec des variables catégorielles
Tu peux non seulement colorer tes points, mais aussi changer leur forme (shape) selon une autre variable catégorielle. Par exemple, ici, on distingue les points par le type de transmission (automatique ou manuelle, avec la variable am).
ggplot(data = mtcars, aes(x = hp, y = mpg, color =as.factor(cyl), shape =as.factor(am))) +geom_point(size =3) +labs(title ="Consommation vs Puissance avec type de transmission et cylindres",x ="Puissance (hp)",y ="Consommation (mpg)",color ="Cylindres",shape ="Transmission (0 = Auto, 1 = Manuelle)")
Astuce : Utiliser shape et color en combinaison est parfait quand tu veux visualiser plusieurs variables catégorielles. Cela rend ton graphique plus riche en informations sans devenir trop chargé.
N’oublies aussi pas que certain.e.s de tes lecteurices seront atteints de Daltonisme, ou alors auront des difficultés à distinguer les couleurs. Pire, imagine que ton plot est imprimé en noir et blanc. Il est toujours bon d’utiliser des formes différentes.
4. Changer la transparence (alpha)
L’argument alpha est particulièrement utile lorsque tu représentes des points ou des distributions qui se chevauchent, comme des histogrammes ou des densités. En ajustant la transparence des couleurs, tu peux éviter que les distributions (ou les points) ne se masquent entre elles et voir clairement où les données se concentrent.
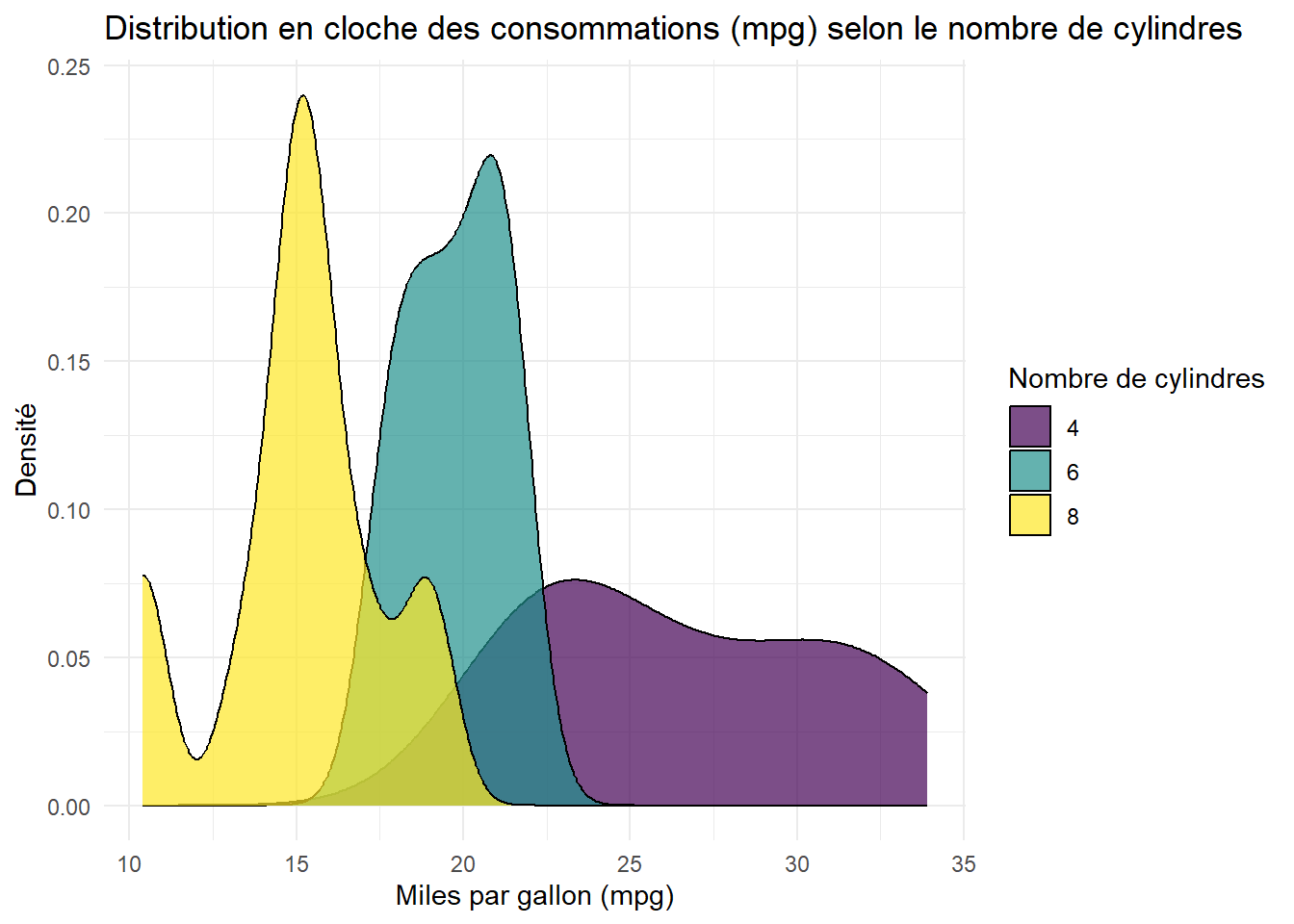
ggplot(data = mtcars, aes(x = mpg, fill =as.factor(cyl))) +geom_density(alpha =0.7) +labs(title ="Distribution en cloche des consommations (mpg) selon le nombre de cylindres",x ="Miles par gallon (mpg)",y ="Densité",fill ="Nombre de cylindres") +scale_fill_viridis_d() +# Application de la palette Viridis pour variables discrètes# scale_color_viridis_c() + # Palette Viridis pour variable continue si tu veux essayer ! Moins adapté ici !theme_minimal()
Astuce : Utilise l’argument alpha pour éviter que des points/courbes/barres superposés ne masquent des informations importantes dans des graphiques denses. Dans un nuage de points, cela te permet de voir les zones de densité.
Explication :
geom_density(alpha = 0.7) : Courbes de densité avec une transparence de 70% pour que les courbes se chevauchent tout en restant lisibles.
scale_fill_viridis_d() : Utilise la palette Viridis adaptée aux variables discrètes (d pour “discrete”).
labs() : Ajoute des titres et étiquettes pour les axes, ainsi qu’une légende
5. Combiner aes() avec des barres
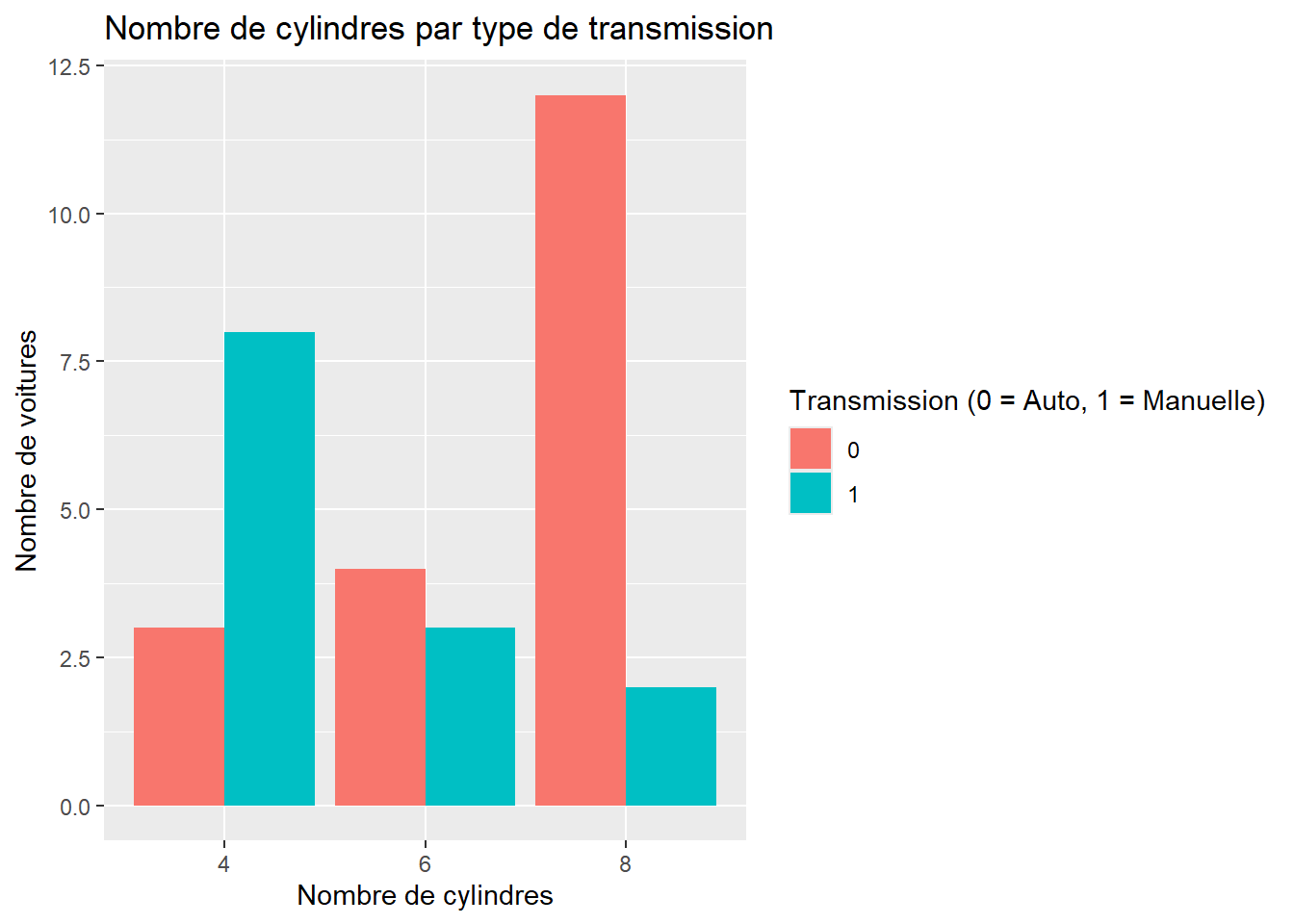
Les mêmes principes s’appliquent avec des graphiques en barres. Ici, nous colorons les barres selon le type de transmission (variable am) et utilisons la position “dodge” pour afficher les barres côte à côte.
ggplot(data = mtcars, aes(x =as.factor(cyl), fill =as.factor(am))) +geom_bar(position ="dodge") +labs(title ="Nombre de cylindres par type de transmission",x ="Nombre de cylindres",y ="Nombre de voitures",fill ="Transmission (0 = Auto, 1 = Manuelle)")
(Oui oui, nous avons déjà vu cela plus haut, mais j’essaie de faire des liens !)
6. Ajouter une couleur en fonction d’une variable continue
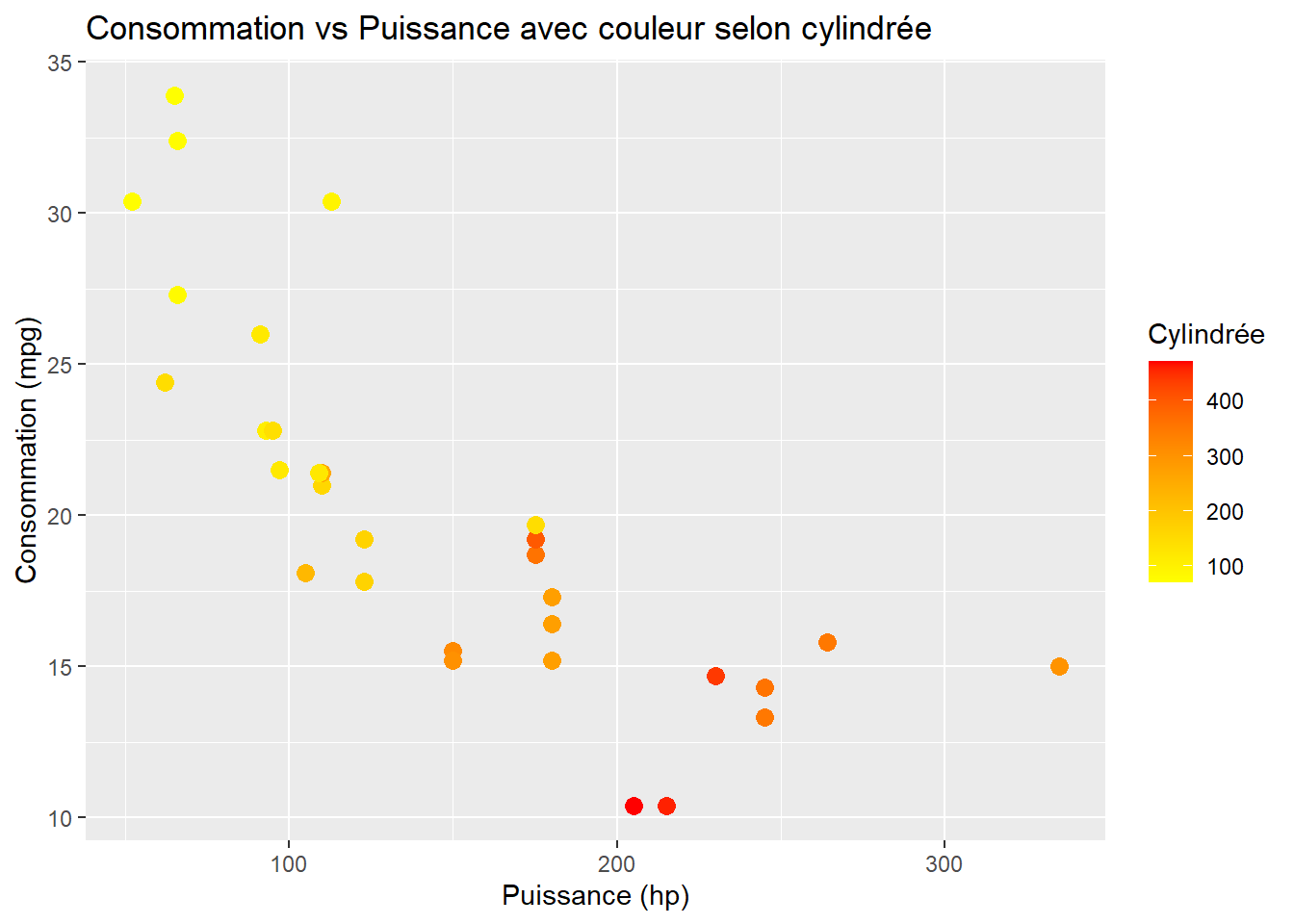
Enfin, tu peux colorer les points en fonction d’une variable continue pour illustrer une relation progressive (par exemple, ici avec la variable disp, la cylindrée du moteur).
ggplot(data = mtcars, aes(x = hp, y = mpg, color = disp)) +geom_point(size =3) +scale_color_gradient(low ="yellow", high ="red") +labs(title ="Consommation vs Puissance avec couleur selon cylindrée",x ="Puissance (hp)",y ="Consommation (mpg)",color ="Cylindrée")
Astuce : Utilise scale_color_gradient() pour contrôler la transition de couleurs lorsque tu utilises une variable continue dans color. Cela te permet de voir facilement des relations entre plusieurs variables continues.
7. Récapitulatif des options de aes() :
x et y : Variables pour les axes X et Y.
color : Colore les points/barres en fonction d’une variable (catégorielle ou continue).
size : Change la taille des points en fonction d’une variable continue.
shape : Modifie la forme des points selon une variable catégorielle.
alpha : Ajuste la transparence des points ou barres.
fill : Remplit les barres/objets fermés en fonction d’une variable catégorielle.
facet_wrap() : Crée des sous-graphes basés sur une variable catégorielle.
10. labs() : Titres et légendes
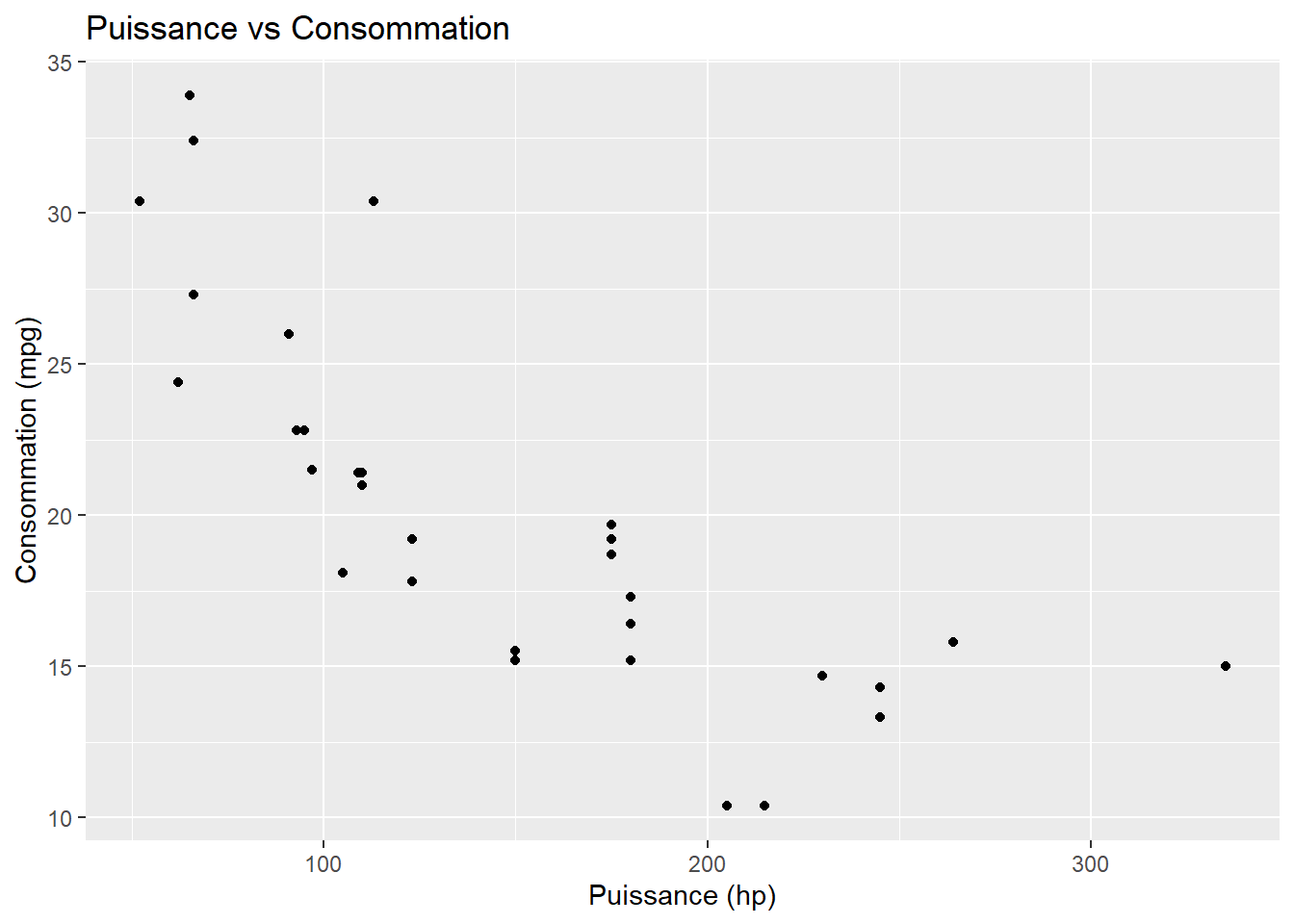
Description : Personnalise les titres, étiquettes et légendes.
ggplot(data = mtcars, aes(x = hp, y = mpg)) +geom_point() +labs(title ="Puissance vs Consommation", x ="Puissance (hp)", y ="Consommation (mpg)")
Astuce : Ne néglige jamais les titres et étiquettes ! Ils aident à clarifier le message que tu veux faire passer.
11. theme() : Personnaliser l’apparence
Description : Modifie l’apparence générale du graphique (police, fond, taille des textes, etc.).
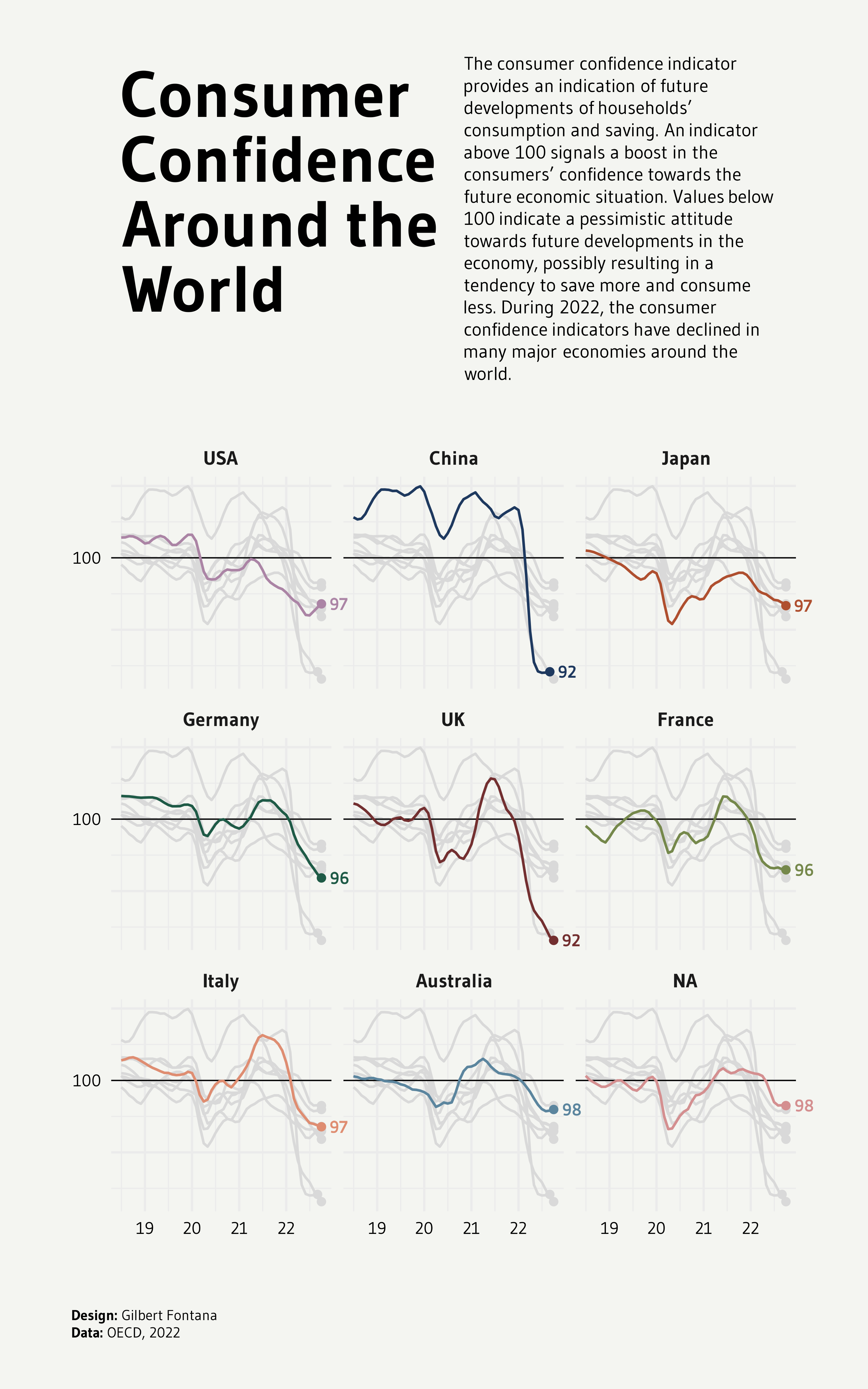
J’y ai par exemple trouvé le code pour ce graphique à lignes multiples. Il montre l’évolution d’une métrique (la confiance des consommateurs dans le monde) au cours des dernières années. Chaque élément du graphique multiple présente l’évolution d’un pays spécifique.
Ce qui est inéressant, c’est que tous les autres pays sont également affichés, mais avec un effet estompé. Ainsi, l’évolution du pays ciblé est clairement mise en évidence, tout en permettant de la mettre en perspective avec les autres pays.
Incroyable non ?! Voyons comment le construire avec R et le tidyverse.
Code
library(tidyverse)library(janitor)library(showtext)library(MetBrewer)library(scico)library(ggtext)library(patchwork)library(gghighlight)# devtools::install_github("BlakeRMills/MetBrewer")df1 <-read.csv("https://raw.githubusercontent.com/holtzy/R-graph-gallery/master/DATA/dataConsumerConfidence.csv") %>%mutate(date=lubridate::my(Time)) %>%select(-Time) %>%pivot_longer(!date, names_to ="country", values_to ="value") %>%na.omit()#### MISC ####font <-"Gudea"font_add_google(family=font, font, db_cache =TRUE)fa_path <- systemfonts::font_info(family ="Font Awesome 6 Brands")[["path"]]font_add(family ="fa-brands", regular = fa_path)theme_set(theme_minimal(base_family = font, base_size =10))bg <-"#F4F5F1"txt_col <-"black"showtext_auto(enable =TRUE)scale_color_met_d("Redon")caption_text <-str_glue("**Design:** Gilbert Fontana<br>","**Data:** OECD, 2022")p1 <- df1 %>%ggplot() +geom_hline(yintercept =100, linetype="solid", size=.25) +geom_point(data=df1 %>%group_by(country) %>%slice_max(date),aes(x=date, y=value, color=country), shape=16) +geom_line(aes(x=date, y=value, color=country)) +gghighlight(use_direct_label =FALSE,unhighlighted_params =list(colour =alpha("grey85", 1))) +geom_text(data=df1 %>%group_by(country) %>%slice_max(date),aes(x=date, y=value, color=country, label =round(value)),hjust =-.5, vjust = .5, size=2.5, family=font, fontface="bold") +scale_color_met_d("Redon") +# Spécification correcte de la palettescale_x_date(date_labels ="%y") +scale_y_continuous(breaks =c(90, 95, 100, 105, 110),labels =c("","","100","","")) +facet_wrap(~factor(country, levels=c('USA', 'China', 'Japan', 'Germany', 'UK', 'France', 'Italy', 'South Korea', 'Australia'))) +coord_cartesian(clip ="off") +theme(axis.title =element_blank(),axis.text =element_text(color=txt_col, size=7),strip.text.x =element_text(face="bold"),plot.title =element_markdown(hjust=.5, size=34, color=txt_col, lineheight=.8, face="bold", margin=margin(20,0,30,0)),plot.subtitle =element_markdown(hjust=.5, size=18, color=txt_col, lineheight =1, margin=margin(10,0,30,0)),plot.caption =element_markdown(hjust=.5, margin=margin(60,0,0,0), size=8, color=txt_col, lineheight =1.2),plot.caption.position ="plot",plot.background =element_rect(color=bg, fill=bg),plot.margin =margin(10,10,10,10),legend.position ="none",legend.title =element_text(face="bold") )text <-tibble(x =0, y =0,label ="The consumer confidence indicator provides an indication of future developments of households’ consumption and saving. An indicator above 100 signals a boost in the consumers’ confidence towards the future economic situation. Values below 100 indicate a pessimistic attitude towards future developments in the economy, possibly resulting in a tendency to save more and consume less. During 2022, the consumer confidence indicators have declined in many major economies around the world.<br>")sub <-ggplot(text, aes(x = x, y = y)) +geom_textbox(aes(label = label),box.color = bg, fill=bg, width =unit(10, "lines"), # Ajuste la largeurfamily=font, size =2.7, lineheight =1.2, # Réduit la taille de police et augmente l'espacementpadding =margin(l =50) # Ajoute du padding à l'intérieur de la textbox ) +coord_cartesian(expand =FALSE, clip ="off") +theme_void() +theme(plot.background =element_rect(color=bg, fill=bg))# TITLEtext2 <-tibble(x =0, y =0,label ="**Consumer Confidence Around the World**<br>")title <-ggplot(text2, aes(x = x, y = y)) +geom_textbox(aes(label = label),box.color = bg, fill=bg, width =unit(10, "lines"),family=font, size =9.5, lineheight =1 ) +coord_cartesian(expand =FALSE, clip ="off") +theme_void() +theme(plot.background =element_rect(color=bg, fill=bg))finalPlot <- (title+sub)/p1 +plot_layout(heights =c(1, 2)) +plot_annotation(caption = caption_text,theme=theme(plot.caption =element_markdown(hjust=0, margin=margin(20,0,0,0), size=6, color=txt_col, lineheight =1.2), plot.margin =margin(20,20,20,20),))showtext_opts(dpi =600)# Save the figureggsave(here("images", "consumer_confidence.png"),bg=bg,height =8,width =5,dpi =600)
Ou encore ce tutoriel qui explique comment créer une carte choroplèthe en style lego pour visualiser la proportion de personnes pratiquant un sport sur le territoire français. Le style lego est implémenté en R à l’aide des packages ggplot2 et sf. Cet article inclut un guide pas à pas de la construction de la carte, ainsi que le code final reproductible.
library(tidyverse) library(sf)map<-sf::read_sf('https://github.com/BjnNowak/lego_map/raw/main/data/france_sport.gpkg')# Create classesclean<-map%>%mutate(clss=case_when( value<18~"1", value<20~"2", value<22~"3", value<24~"4", value<26~"5",TRUE~"6" ))# Set color palettepal <-c("#bb3e03","#ee9b00","#e9d8a6","#94d2bd","#0a9396","#005f73")# Set color backgroundbck <-"#001219"# Set theme theme_custom <-theme_void()+theme(plot.margin =margin(1,1,10,1,"pt"),plot.background =element_rect(fill=bck,color=NA),legend.position ="bottom",legend.title =element_text(hjust=0.5,color="white",face="bold"),legend.text =element_text(color="white") )# Make gridgrd<-st_make_grid( clean, # map name n =c(60,60) # number of cells per longitude/latitude )%>%# convert back to sf objectst_sf()%>%# add a unique id to each cell # (will be useful later to get back centroids data)mutate(id=row_number())# Extract centroidscent<-grd%>%st_centroid()# Intersect centroids with basemapcent_clean<-cent%>%st_intersection(clean)# Make a centroid without geom# (convert from sf object to tibble)cent_no_geom <- cent_clean%>%st_drop_geometry()# Join with grid thanks to id columngrd_clean<-grd%>%#filter(id%in%sel)%>%left_join(cent_no_geom)# Set offset# (value here is not fixed, it depends on your map, system of coordinates, etc...)off <-2000# Create second centroidcent_off <- cent_clean%>%# Extract longitude and latitude and add offset to longitudemutate(lon=st_coordinates(.)[,1]+off,lat=st_coordinates(.)[,2], )%>%# Drop old geometryst_drop_geometry()%>%# Make new geometry based on new {lon;lat}st_as_sf(coords=c('lon','lat'))%>%# Specify Coordinates Reference Systemst_set_crs(st_crs(cent_clean))# Make map !final_map <-ggplot()+geom_sf( grd_clean%>%drop_na(), mapping=aes(geometry=geometry,fill=clss) )+# Centroid for shaded effectgeom_sf(cent_off,mapping=aes(geometry=geometry),color=alpha("black",0.5),size=0.5)+# 'Real' centroidgeom_sf(cent_clean,mapping=aes(geometry=geometry,color=clss),size=0.5)+geom_sf(cent_clean,mapping=aes(geometry=geometry),fill=NA,pch=21,size=0.5)+labs(fill="Member of a sport association")+guides(color='none',fill=guide_legend(nrow=1,title.position="top",label.position="bottom" ) )+scale_fill_manual(values=pal,label=c("< 18 %","< 20 %","< 22 %","< 24 %","< 26 %", "≥ 26 %") )+scale_color_manual(values=pal)+ theme_customshowtext_opts(dpi =600)# Save the figureggsave(here("images", "sports_map.png"),bg=bg,height =8,width =5,dpi =600)